【Postmortem】AHC043(RECRUIT 日本橋ハーフマラソン 2025冬)

※画像は公式Visualizerよりお借りしています
はじめに
この記事は2025/02/14 - 2025/02/24にAtCoderで行われましたAHC043の解法を紹介するものになります。
はじめまして(orお久しぶりです)、montplusaです。ここ長らく解法記事・参加記をつけておらず、気づけば最後に【Postmortem】とつけた記事を投稿したのはAHC027で一年以上前になっていました。
本記事ではAHC043で提出したプログラムの解法を書き残しておこうと思います。初めてコンテスト中にAIを利用してみるなどいろいろなことがあったので、解法以外の部分にも触れて自身の備忘録としておきます。
気を付けてはいるのですがところどころうっかり打ち間違っているかもしれません。間違いを発見されましたら優しく教えていただけるとありがたいです。
問題の概要
こちらは問題文を見ていただいたほうが早いと思われるので割愛します。簡単に言えば「鉄道で収益を増やし、資金を最大化する」という問題です。
問題文はこちら
各人が鉄道を利用する条件は「家・勤務地それぞれの近くに鉄道駅があり、かつその間を線路・ほかの鉄道駅を通して移動できる」というものであるため、一つの連結成分を大きくしていく形がよさげです。
最終提出の解法
以下、最終提出の概要です。
言語:go言語
詳細略。ただの好みです。
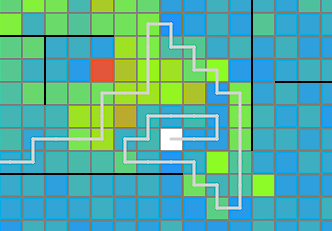
解法:暫定の鉄道網から線路を伸ばし駅を一つ追加するビームサーチ
以下はTwitterで行った解法ツイートです。
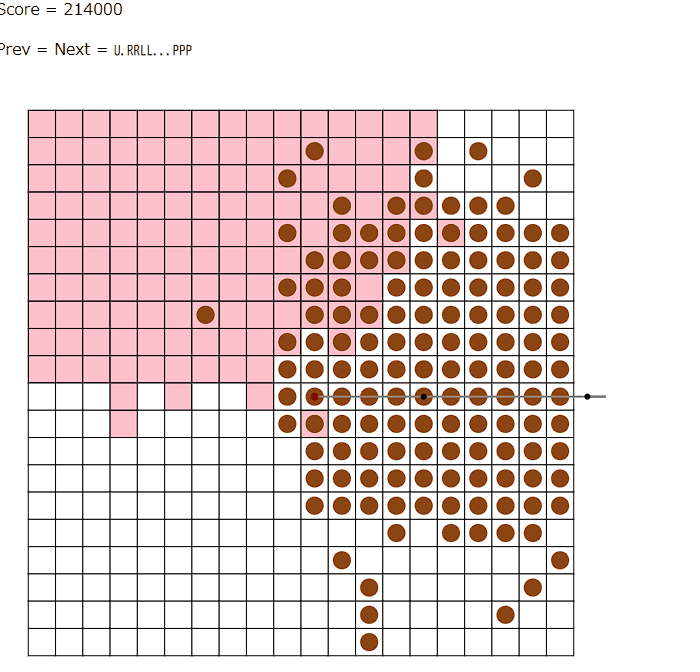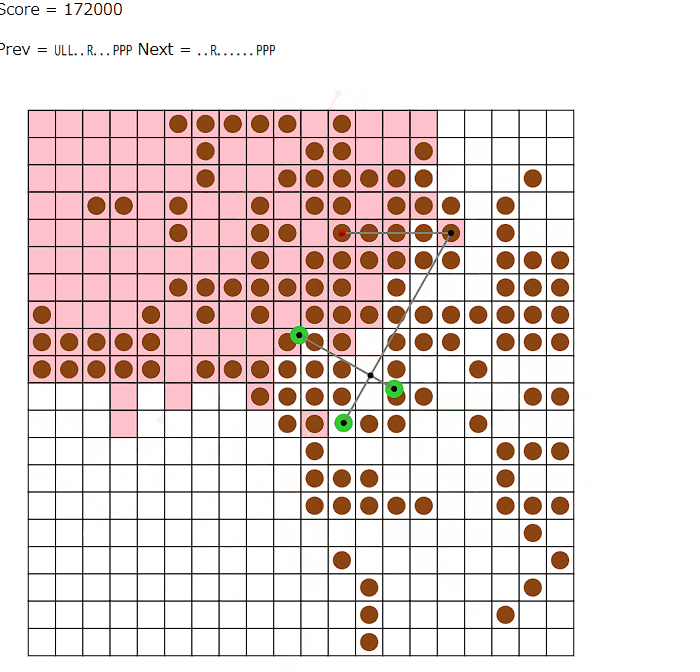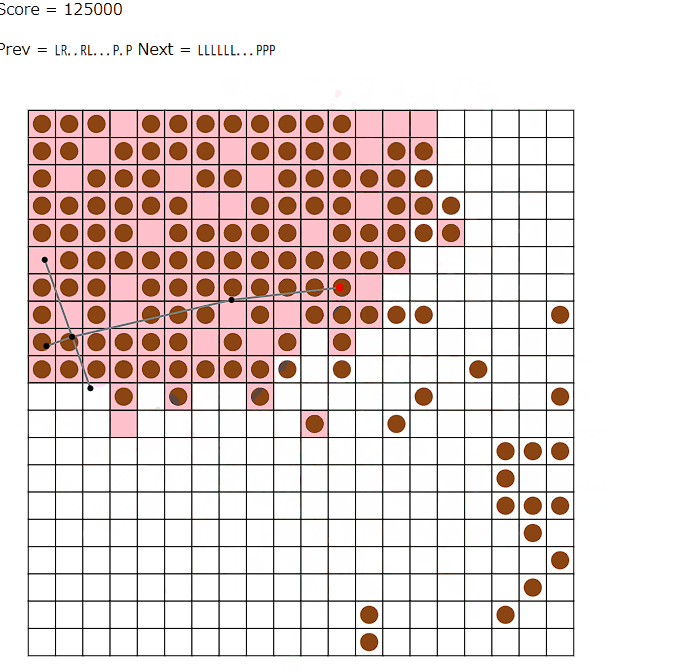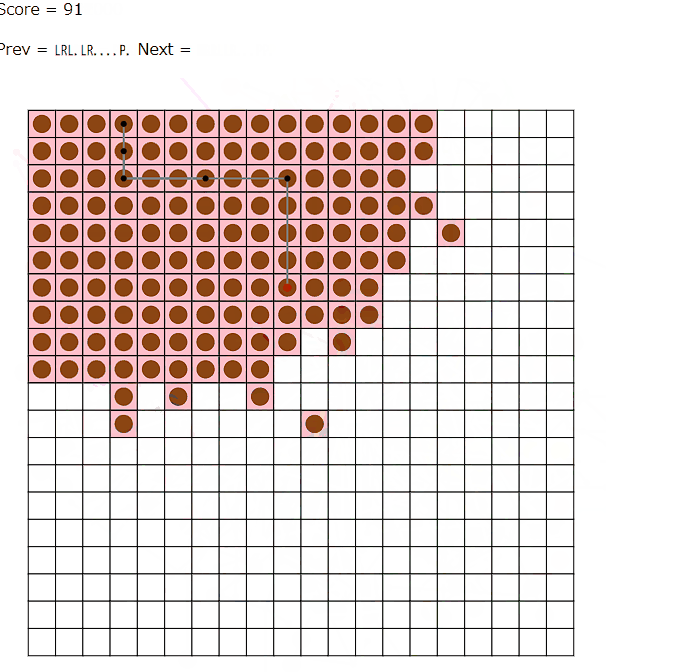
AHC043暫定6位 大まかな方針
— MON.T+α (@montplusa) 2025年2月24日
・駅を頂点、間の線路を辺とした木とみて、構成をビームサーチで決定
・頂点まわりの接続(上下左右)を決定し、貪欲に最短路で辺を再現していく。うまくいかなかったら何回かやる
・辺を付け替えたり、ほかの辺の間にねじ込んで山登り(試行回数10000~100000回)
特にこの解法の肝はビームサーチで駅・接続を決定するところで、その部分についてはTwitterでは以下のように補足しています。
ビームサーチについて
— MON.T+α (@montplusa) 2025年2月24日
・経過ターン数を深さとし、スコアは以降何もしなかった場合のスコア
・家、勤務地の一方しか覆っていないものも多少incomeに反映
・ビーム幅は2~10で、木は次数が4以下かつ「接続方向が大丈夫そうなもの」に限定
これについて、もう少し詳しく見ていきます。
(ここではビームサーチ自体の説明はしません!ビームサーチ自体についてはかつて書いたこちらの前半部分が参考になるかもしれません)
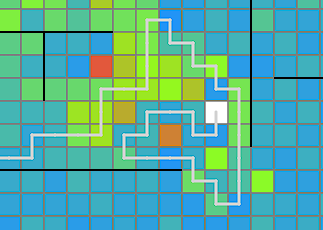
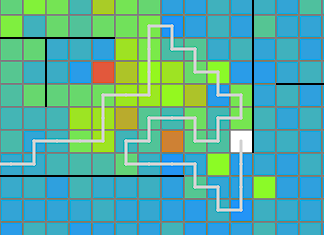
駅を頂点、間をつなぐ線路を辺と考えて木を作る問題とみる
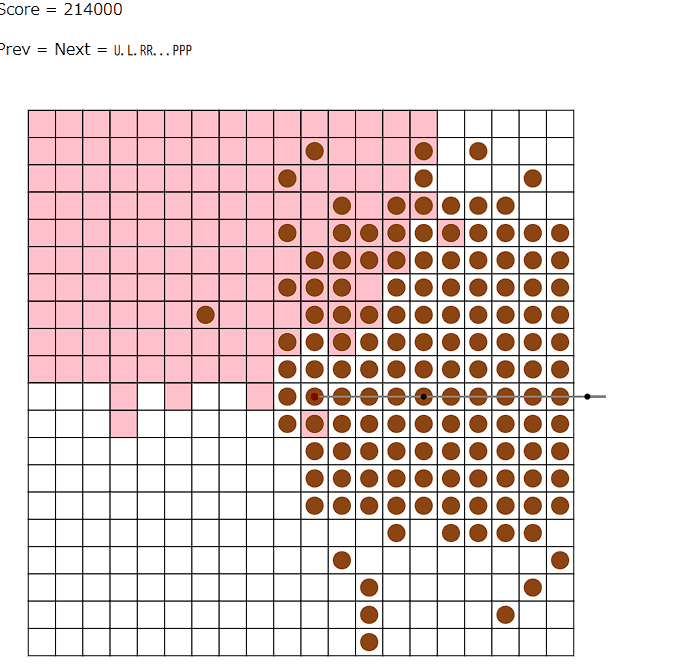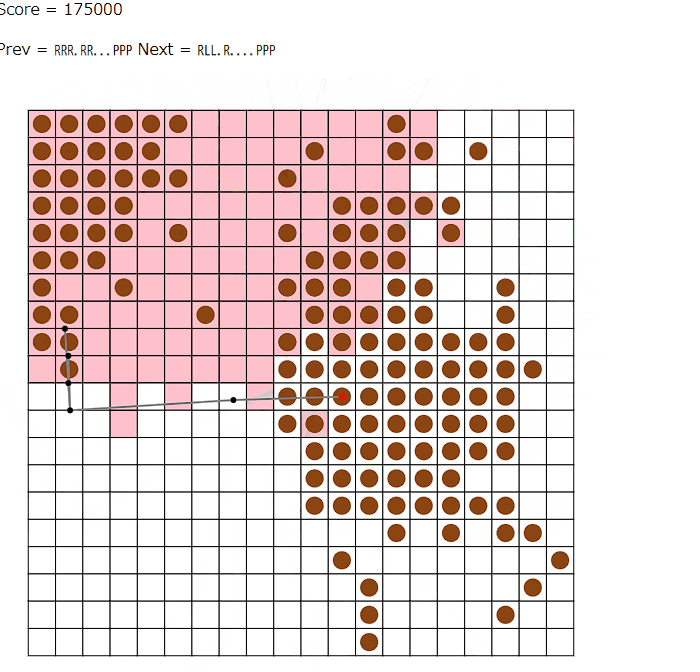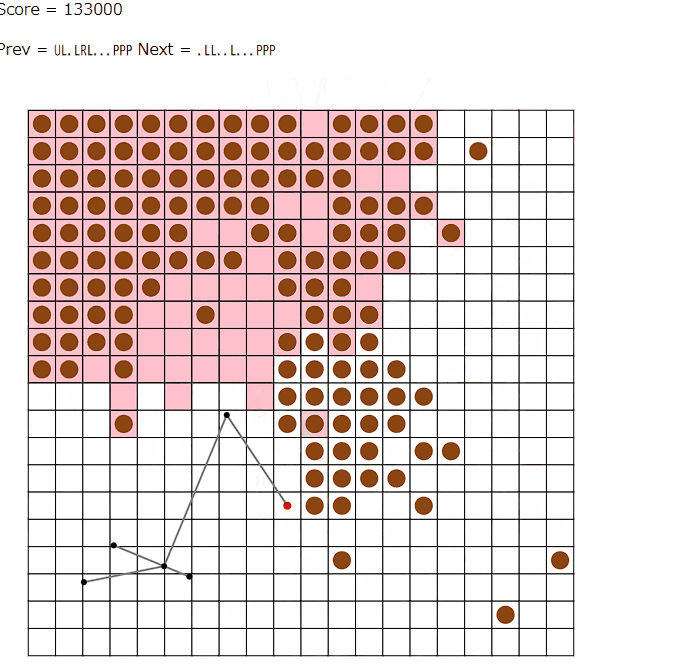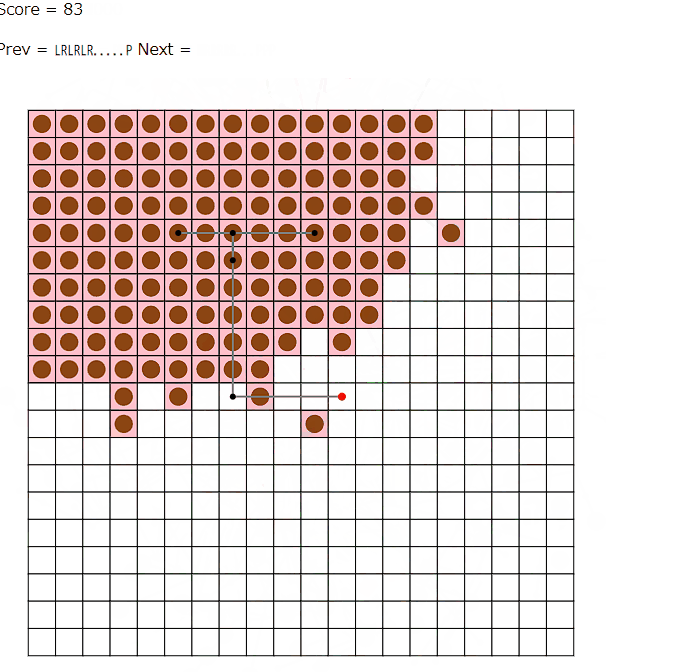
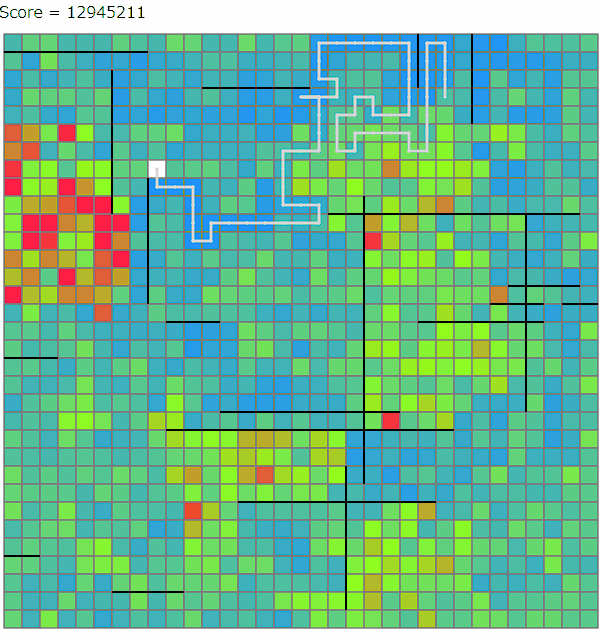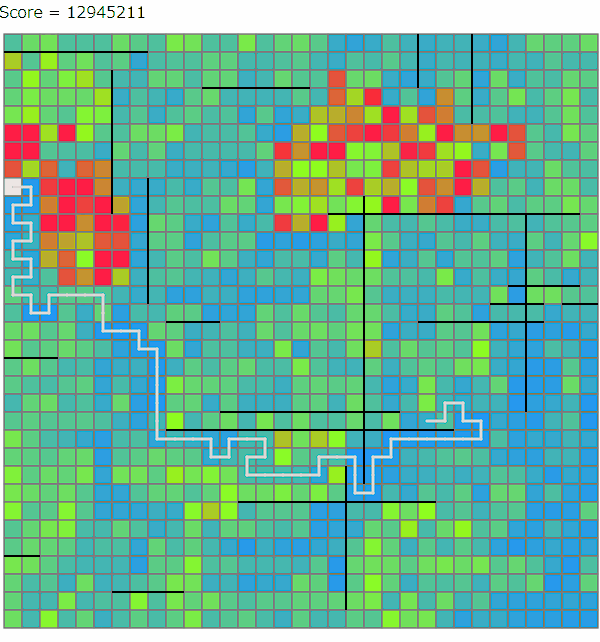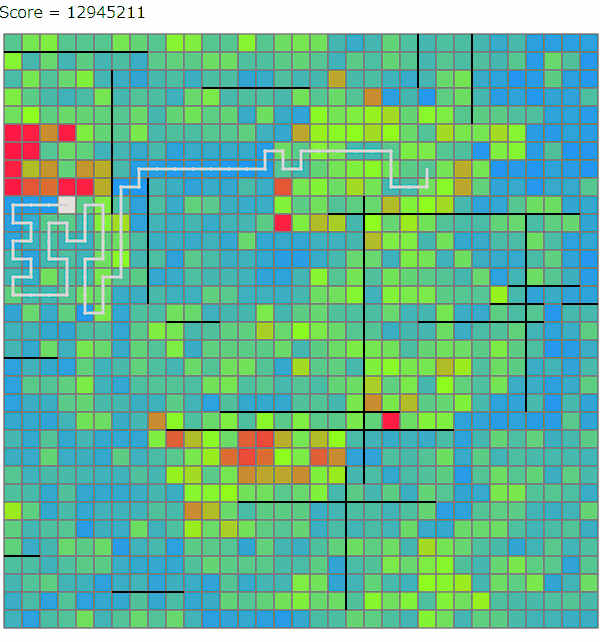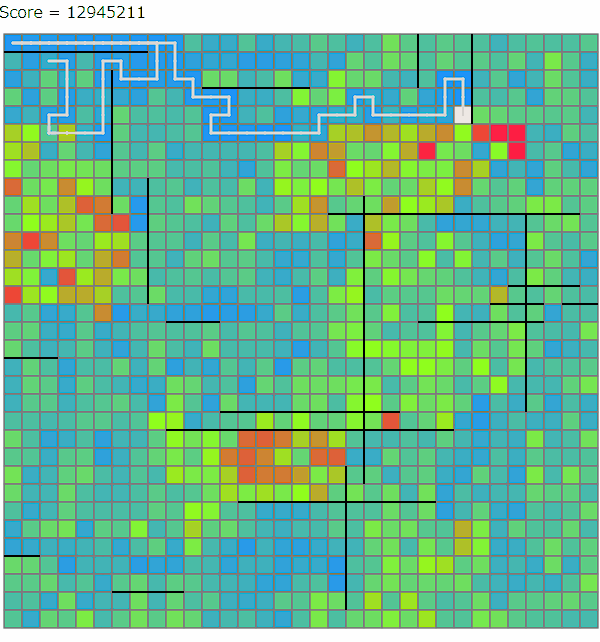
ビームサーチ中(および後処理の山登りによる改善)では、線路をどのマスに設置するかといったところまでは情報として持たず、頂点の座標とどの駅間を線路で結ぶかを情報として持ちます。そのうえで、これらをどの手順で構築するかというのを配列として持っておきます。ChatGPTを利用すると、この段階の解は以下のように可視化できます。

ビームサーチで考えている木は実際に線路が引けそうな形でないと意味がないので、いくつかの制約を設けています。線路が確実に引ける十分条件ではないですが、おおよそ以下のような条件を課しています。
・各頂点から出ている辺の数は4本以下
・頂点に接続する各辺について、最短路方向になるように上下左右への辺の接続を被りなく割り振れる
・各辺を線分としてみたときにいずれも交差していない
これらを満たすような木のうち、ある程度効率的な形をしている木はたいていうまく接続することができるのですが、まれにうまくいかない形になることもありました。なので、実際は事故の頻度を減らすためもう少しコーナー回避用の条件を定めたりしています。
ビームの深さは所要ターン、評価関数は放置した場合のスコア+α
これは比較的素朴な設定かと思います。序盤ではincomeを深さ、ターンを評価にするようなビームも試してみましたが、出力は悪くないものの計算の無駄が多く感じました。良い解がたどるincomeの変遷はかなり飛び飛びなので、有望なものがないincome値の盤面は試さずにスキップするようなつくりを用意すれば問題なかったかもしれません。
評価関数については、incomeに加えて、片側だけカバーしているような人からも10~30%ほどincomeが入るとみなして最終スコアを計算し、そのまま評価値としました。ビームサーチの同じ深さで優劣の比較ができればよいので、他が同条件なら「incomeが多いほうが良い」「片側だけでも抑えられているものが多いほうが良い」「現在の資金が多いほうが良い」という要素とそれらのバランスを鑑みた形です。
深さが800で、各盤面において新しい駅の設置候補は2500個で、各駅「どこかの駅から線路を伸ばす」「既に存在する路線に途中駅として新設する」のどちらか適しているほうを選択するため、ビームの幅はほとんどとることができませんでした(高速化するフェーズまでいけませんでした)。そのため「ビームサーチ」というよりは「保険付き貪欲」といったほうが正しいかもしれません。
ビームサーチ解を山登り
ビーム幅が狭いこともあって出力を見ると明らかに改善の余地があるものが出てくることがあります。最終提出では、これらをシンプルな遷移によって改善していきます。
1.incomeが2000を超えたあたりから、「最終的に駅に置き換える予定だがまずは線路を設置する」といった事象が発生しないようにする
1の改善はすでにある程度お金に余裕がある状態においてターン数を削減するための工夫です。こののちに以下の変更を行い、実際にシミュレートしてみて改善していたら採用していきます。
2.駅の位置を周囲2マスのどこかに移動
3.駅を他の駅区間に挿入
4.他の駅から線路を引っ張ってくる
(最終日付近に書いたものですが、これに駅設置順swapを入れて高速化すればたぶん焼けます・・・)
ビームサーチ解をもとに線路を構築
ビームサーチは線路の敷設情報を持っていないので実際に線路のルートを確定させる必要があります。順番としては
・ルートに選択肢のない辺は先に確定させる(水平・垂直方向の辺)
・頂点での辺の正式な接続方向を割り振る
・最短経路方向に順番にひく(どうしてもぶつかってしまう場合は先にひいていた辺を消去して線路を引き、消去した辺を引き直す)
という順序で処理しています。
最後はこれをActionのqueueとしてもっておき、800ターンを愚直にシミュレートします(お金が足りていたら「ActionQueueの先頭を適用」そうでなければ「Wait」)
工夫点
もがいて改善したポイントとしては、
・最後にActionQueueを適用するところで、「ターンt1を過ぎてからはWAITしない(駅が立てられないなら次の線路敷設・その次の線路敷設を行う)」として、このt1を全探索する
・最後のシミュレーションで、「ターンt2を過ぎてからはずっとWAITする」としてこのt2を全探索する
あたりがあげられます。
最終提出にある残骸(ボツ解法)
・家・勤務地の被覆焼きなまし
シミュレーション抜きに駅数や中心からの距離だけでだけで焼きなまそうとしたもの。家・勤務地のペアで初めてincomeになるため、期待した効果は得られなかった。
・開始数駅だけの焼きなまし
頑張ればビームサーチと同じくらいの解が出たので望みはある(なんならこれで序盤の候補列挙してビームサーチに投入すれば強かった説はある)が、焼きなまし練度が足りず性能不足でボツ。
・・・もしや、練度起因で焼きなまし解法が棄却されてないか?
AHCで初めてAIを使用してみた話
これは何かとホットな話題なので慎重に言葉を選んで書きたいと思います。
今回、AHCで初めてAI(ここでは特にChatGPTのo3-miniのこと)を利用しました。コンテスト中で使用した部分は
・ビームサーチで用いたグラフ情報のビジュアライザ数種
・頂点と辺の情報からグリッド上に線路を起こしてもらう処理(最短経路で引いたり、衝突がさけられないなら引き直したりする処理)
の二点です。
Visualizer

もともとデバッグ用に構築順に「Vertex {座標}」「Edge {座標} -> {座標}」といった出力をして目視で確認していたのですが、これを可視化するものを作成しました。cssが間違っていてビジュアライズ結果が縦長だったりはしましたが、ちょっとした手修正だけですぐにこのクオリティのビジュアライザが用意できたのは純粋に驚きでした。以降、最終日まで線路のルーティング失敗ケースが後を絶たなかったので、このツールには大変お世話になりました。
グリッド上に線路を起こしてもらう処理
これは素朴なビームサーチでそれらしい構築手順ができたものの、最短経路でつないでいく(場合によっては衝突を解消する)処理を書くのが億劫になっていた実装イヤイヤ期の出来事でした。該当部分のロジックは、
・まず最初に頂点に対する辺の接続方向を決定
・BFS(あるいは事前計算しておいた距離)をもちいて繰り返し最短路を求め確定させる
・ぶつかるなら対象の辺を消し再構築
という形が頭の中にあって、重ため(だけどロジックとしては簡素)の実装に感じていたためAIに書いてもらえないかと考えました。
で、出てきた結果はというと・・・。AIは悪くないのですが、事前情報が足りず思っていた挙動のものは出てきませんでした。修正をお願いしたり、最終的には手で直したりしたところとしては以下のようなものがありました。
・座標の取り方、方向が違う
・一次元配列化して渡したものを2次元に戻す
・最短路じゃない(迂回を考慮していた)
・衝突時は上書きして再ルーティングしない
などなど・・・。難しいのが一部のケースで発生するバグで、今実装中のロジックにバグがあるのか、AIコード部分でバグがあるのかが毎度わからなくなっていました。結果として、メインで時間を割きたかったビームサーチ部分や焼きなましのトライよりもルート決めの修正時間が長くなってしまい、かなりの損失でした。
使ってみた全体の感想としては、「一度目の応答は素晴らしいが、修正は応答を重ねるごとにちょっとずつうまくいかなくなる」というような印象を受けました。大きなプログラムを作ってもらおうとしたときに情報を小出しにして少しずつ構築・修正しようとしていたのですが、この「修正」部分がどうやら苦手そうで、前の部分を引きずっていたりしていました。関数の改良をお願いしたら同名の関数の二つ目を作って一つ目が残っていたり、XY座標ではなくRow,Col座標に変更したのに名称は混在していたりなど。
プログラムで採用していた部分は途中からは自分でバグ修正・仕様追加することにして、最終的には魔改造された何かになってしまいました・・・。
(具体像があるなら最初のやり取りで網羅的に伝えるか、自分で実装しようねという教訓になりました。いろいろ解釈が残る伝え方をしてしまっていたのがおそらくよくなくて、本来人に雑に頼んだら仕様確認で聞き返されるはずの部分が全然返ってこないという状況でした。)
おわりに
ここまで見てくださった方、ありがとうございます。
日本橋ハーフマラソンに参加するのはかれこれn度目ですが、毎度かなり難しいなかでよさげな貪欲的な操作があり、段階的にプログラムを改善していく道筋が考えられたコンテストだなあと感じています。また、アルゴリズム的に高度な要素は少ないが実装は大変なところが多く、まさしくマラソンのようなコンテストでした。
改めて、このような大会を開催してくださった皆様、コンテストで戦った皆様、ありがとうございました!それではまた次回のコンテストで・・・。
おまけ
・今回は解法を決めるまでのところを日記として書いてみた。頭の中で抱いた最適化の感覚を文章化するのって難しいなあと思ったり。
・最後のフェーズ以外で線路のルートを陽に持っていないのは、駅を間に差し込んだり、駅を途中から延ばすような遷移を考える場合に未確定であるほうが圧倒的に自由度が高いと感じたため。私の実力で復元できるだろうという自信はありませんでしたが、復元をあきらめたら大敗するだろうと思っていたのでやるしかありませんでした。
・そういえば重複盤面の消去後でしようと思って忘れてた・・・。幅2なのであんまり影響はありませんが・・・。
・そういえば今回のビームサーチは「線路の先置き」があるためあんまり足並みがそろってなくて、深さをターン数にするのは本当は適切ではないと思う。幅2なのであまり影響はありませんが・・・。
・今回の問題、頑張れば焼きなましが使えると思いつつ、雑に作ると多分本来の意味(?)で焼きなませてはなくて、初期解周りの局所的な部分を探索することになると思われる。
・詳細順位表を見て雑に所感を述べてみる。

うん・・・。良くも悪くも安定型というか、今回も例にもれず「大きな苦手はないが、best解はほとんどない」プログラムっぽい。全パラメータで通用する解法を考えている節があるのかも?なお、Mの分布は偏ってるので、50~100あたりを軽視しすぎたのかもしれない。
・saharaさんとrhooさんがそれぞれ延長戦で線路先引きをしたものを提出してみんなを突き放していた。線路先引きによる改善幅が二人で結構違うのも面白いし、saharaさんが先引きなしでM大K大のケースで戦えてたのも面白い。
・Jirotechさんとはだいぶ傾向が近そうで(割と過去のコンテストでも親近感があるかもしれない)同じく線路先引きもされていたが、M大の部分で同じように伸びきれなかったのは後処理を山登りにしてしまったところにありそう。
なんか詳細順位表にいる人に言及する流れっぽくなったのでちょっとだけ触れていきます・・・(不快な人いたらDMで教えてください。そっと修正しておくので)
・nikajさん(USAさん?)は、AHC038でもそうだったんですが、得点がどんどん伸びて行って追いつけなくなるイメージ。序盤にNNを使う発想は確かになあとおもいつつ、私ならうまくいかず撃沈しただろうなという・・・。
・Rafbillさんは、まだ解法ツイートは見ていない気がする。Mが大きいケースで強いので、おそらくしっかり焼きなまし側をする解法と予想。(提出見に行けばよいのでは?)ビームサーチ->焼きなましっぽい?
・MathGorillaさんは、このところずっと強い&成長中のイメージ。短期コンの延長も走ったりしている印象だし、おそらく沼にはまったと予想。(校正中の私:何を予想してるんだこれ。上の文体に引っ張られたか。もうちょっと解法側の話を書いてほしい)解法の話だと、序盤だけビームサーチをするは確かにそう。焼きなましの一般的な近傍とこの問題のrawscoreが苦手としているのは最初部分で、以降は割とswapなどが効く部分が多いと思う。と、過去の日記の自分も言ってる。が、私はできませんでした。
・wleiteさん。週末の段階で1位に立っていて、「絶対届かんやろ」と思っていたが、最終日になってようやく追いついた。解法ツイートはたしかなかったと思う。提出を見てみるとどうやらビーム部分がなさそうな雰囲気が・・・?最序盤部分ってどうやって焼くんだろう?
・yokozuna57さん。M中くらいが一番強いというちょっと面白いグラフ。解法ツイートを見かけていない気がする。M大が少し苦手そうなのはビームサーチっぽくて、M小も少し苦手ということは、もしやM小のケースで計算リソースを余らせているのではないか・・・?
・tishii24さん。かなり得意ケース不得意ケースが分かれていそうで、M小は完敗。解法ツイートは見ていない気がするが、提出を見る限りビームサーチ。M小のケースが強いということは、後処理前の純粋なビームで負けていそう。
・AHC042の延長戦で気づいた反則テクニックがあって、AIを使って提出をRustに変えるという方法がある。今回はそれ以前にするべき根本的な改善があったので採用しませんでしたが・・・。
(短期コンのような最適化問題の構造が素朴(≠問題が簡単)だとあたり方針同士は高速化勝負になりがちで割とダイレクトに差が出る印象がある)
AHC042の延長戦では1位に立ってから何回も提出するも・・・

じつは1位になってからは言語変えてビーム幅増やしていっただけというオチ

こうなってしまうと新実装にも時間がかかるので、実質ラスサブ宣言になってしまうのもコンテストで使いにくいところ。
AHC043 解法決定から枠組み完成までの日記
コンテスト日記
※これはPostMortem・解法解説記事ではありません
コンテスト序盤の考察から数日で順位表を駆け上がる部分を日記として残しておこうと思い書いています。駆け上がれるかどうかはわかりません。長期コンテストの立ち回り方のサンプル1として参考になれば幸いです。
02/14
問題を見た。RECRUITさん作問の日本橋ハーフマラソンらしい問題だと感じた。ここ何回か参加した限りのハーフマラソンの問題の特徴は以下。
・おなじみの最適化手法が使える単純な構造が見当たらない
・数式的ではなくゲームに近い
そのため、最適化の「正しさ」みたいなものが保証できることがあまりなく、評価に趣向を凝らして貪欲に近い行動を行うか、行動を実際に適用してスコア計算をするなどが有効。
またデータ規模もAHCの最適化対象としては大きめで、これらがおなじみの最適化手法を妨げている原因の一つでもある。
今回も例にもれず同じような性質を持っているので大枠の取り組み方は同様で問題ないだろう。ただ、乱数要素がないため、問題を適切に変換すれば山登り・焼きなまし・ビームサーチが使えるだろう。
純粋に各地点間をつなぐとM本の鉄道を引けばよいが、家の密度やコストを考えるとtreeを作るのが妥当だろう。
keyPointになりそうな部分を押さえておく。
鉄道の交差禁止
平面上に鉄道を引く都合上交差はできない。厳密には鉄道駅を置くことで交差できるが、コストに余裕がないと無理であるので、基本は考えない方針で行きたい。
そのため迂回が必要になるが、50*50(=2500)点間の距離計算は何度も走らせられるものではないので、「最短距離でつなげられるものをつなぐ貪欲」みたいなものはナイーブに作っても間に合わない気がする。(いや定義にもよるが間に合うか)
いったん手動解を生成する。最後まで作るのは疲れる(かつ、重要なのは序盤の拡大再生産っぽい部分?)と思うのでIncomeが500になるまでやってみる。
大体400ターンくらいで達成し、残り400ターンは放置。

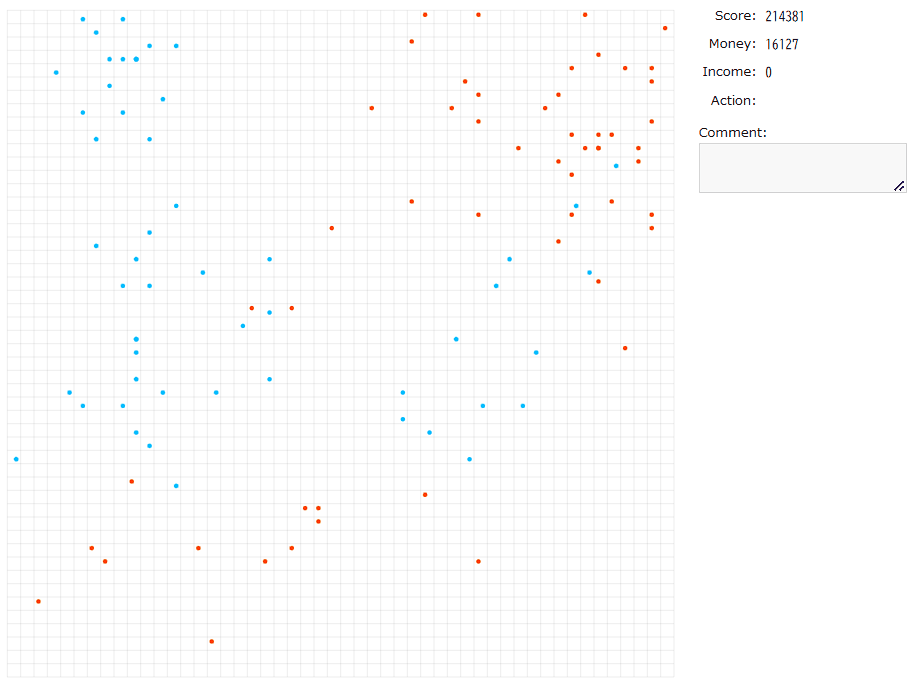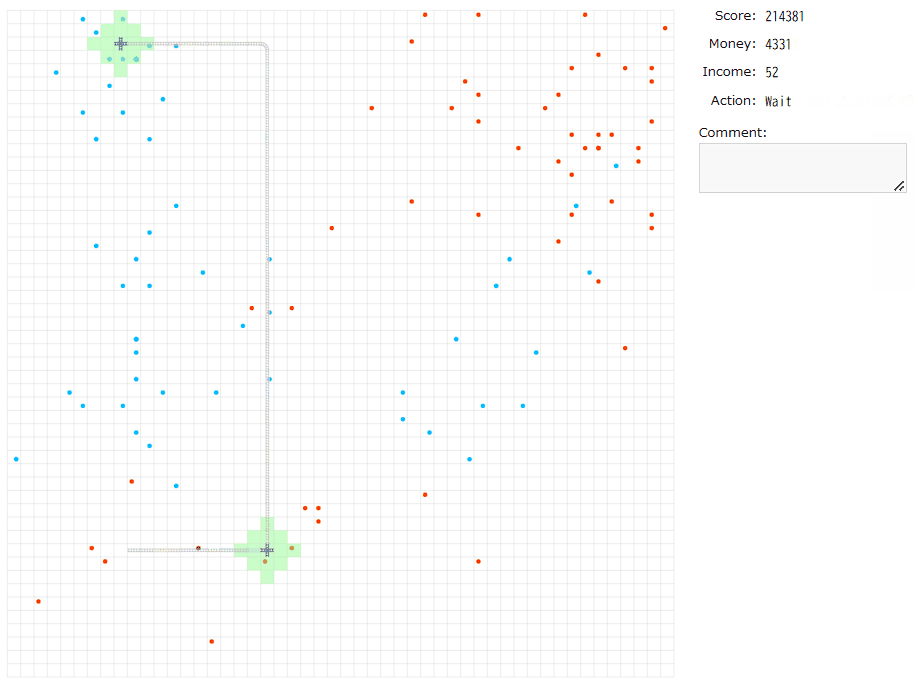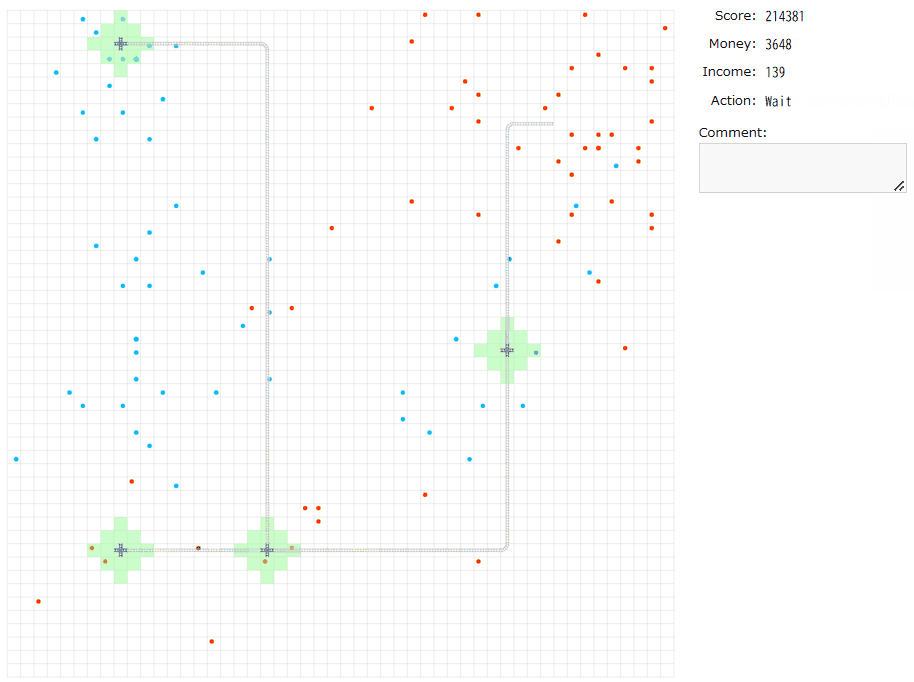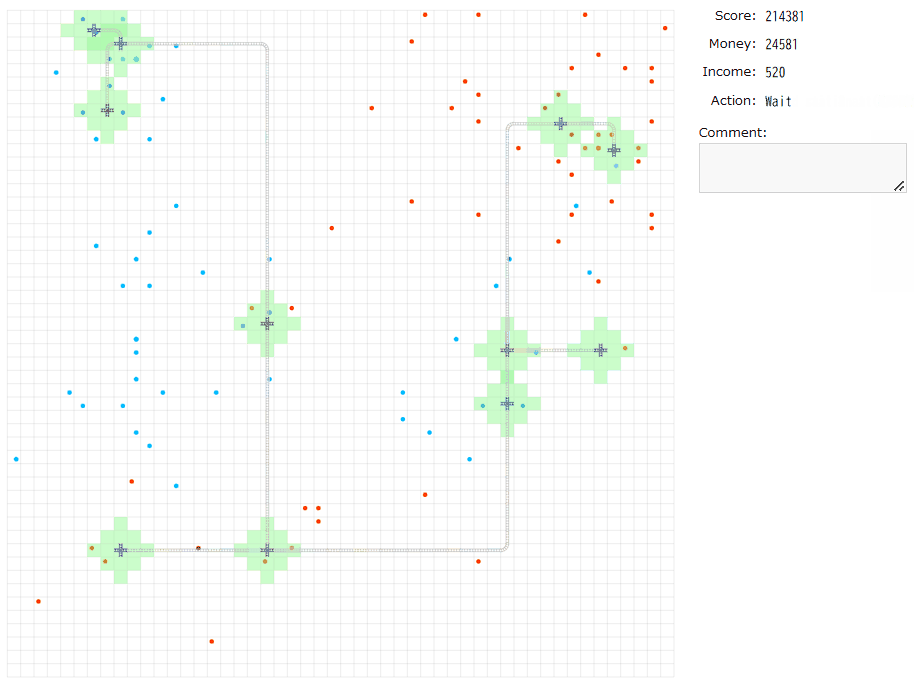
実験してみて再確認できたことは、
・最初につなげる一組はある程度遠いほうが良く(incomeが少なく2組目が遠いため)、段階的に大事ではなくなってきそう。これは直感的にincomeで5000を稼ぐのにかかるターンあたりと対応づく。
・一つの駅がたくさんの家・勤務地をカバーしているほうが良い。ただ、必ずしも全被覆をめざす必要があるのかはわからなかった。資金のインフレ率次第か。
・貪欲につなぐのが最適とは限らない(かつ、良いつなぎ方は評価しにくい)。1組目のincomeが大きいことが大事だが、2組目、3組目がスムーズに繋がられなければ序盤のインフレスピードが思ったより伸びない。上のGIF解は序盤の組選びを失敗していそう。
・順位表はまだまだ圧縮されそう。人の少ないseed0で雑貪欲、後半放置でも初期の10倍の資金になったので、おそらくもっともっと稼げるのだろう(いまは初期状態でも1Gある)
ひとまず、初日のアイデアを寝る前に書いておく。(手動解で確かめた感触ではまあまあ悪くなさそうなので、明日の用事中に改善が思いつかなければ、このまま最終方針になるかもしれない。)
案1
・被覆(駅の位置)を焼きなましor山登りで決定。
・駅の接続・接続順をビームサーチ(treeを先に決めたらそれに対する最適が求まったりしないよな・・・?)。
評価関数はincomeベースに残資金を加える。深さはターン数が適切か。
(逆にターン数ベースの評価値、深さincomeでもよいが、ビームが細く、無駄な計算も多そう)
・ビーム結果にしたがってつなげる(シミュレーション)。
駅の接続は接続先が4つを超えないようにすれば、適切に離れた駅配置なら問題ないはず・・・?
案2
treeの形状を焼きなまし部分で決定する場合。ビームサーチにtreeの形も決めさせるのは少々酷なので・・・
・被覆(駅の位置)とそれらの接続を焼きなましor山登りで決定。
・駅の接続順のみビームサーチ
・ビーム結果にしたがってつなげる(シミュレーション)。
被覆決定時に接続も焼くことで実際につなげるの際によりつなぎやすい配置になっていそう。
寝る前の今の私の意見としては案2を採用したい。
いずれにせよ、冒頭の通りハーフマラソンは性質上実際にやってみないことにはうまくいくかわかりにくい問題なので、途中で再検討する可能性がある。
2/15
予定のため最終決断はまた今度。入出力の整備はできたらする。のつもりだったがある程度考えを固めている。
寝ている間に「序盤が重要なら序盤の数個の設置を頑張って計算→後半は惰性で頑張る」みたいな時間リソースの配分がよいのでは?という気持ちになる。
以下、昨日から考えていたものもあるが忘れるといけないのでメモしておく。
隙間時間にできるだけもう少し正確に分析しておく。今回の資金増加は
・incomeが少なく、設置コストが律速であるうちはincomeをincomeに比例してあげることができる(これは微分が自身に比例しているととらえてもよい)ため指数関数的な成長を見せる。駅設置のインターバルが調和級数に近いふるまいをすることからも間違いないだろう。
・incomeがある程度増えてきたら、1ターンに1個しか置けないことが律速になる。人口が非常に少ない場合、このフェーズはないかもしれない。incomeは一定ペースで増え、総資産は二次関数的な成長を見せる。
・(あまりに都合よく拡大できた場合に限り)すべての人が利用するようになりincomeの成長は止まる。ここからは一次関数となる。
以上の流れにおいて、指数的フェーズ、二次関数フェーズ、一次関数フェーズはincomeという指標によってのみ一方向に進行していく。incomeを深さにを利用したビームサーチはその意味で強い合理性がある。同じincomeでも早いターンに到達できたものが最終的に資金が多くなるため、評価関数にも合理性がある。
序盤の展開については被覆を考える前に決定したほうが良い可能性もある。income500くらいまでの駅の設置順・接続を模擬的に所要ターンを見積もることで評価できる。有力候補が簡単に列挙することができるならビームサーチが効くが、愚直に駅候補を2500点で考えると有効な検索ができない。家と勤務地のペアのうち一方を抑えているものの相方付近に限定すれば、ある程度のビーム幅でシミュレーション可能か。人口の多いマップでは候補が多い代わりに500達成に必要な家も少ないので、何とかなると思われる。(厳密距離さえ使わなければ候補に対して評価値の計算はO(1)でできるため、2500候補と考えても幅100くらいできたりしないか・・・?)(冷静に考えたら、そもそも10^3ってそんなに大きな数字か?)
初期資金が11000ならはじめは距離15程度の二点しかつなげられず、20000ならギリギリ任意の二点がつなげられる。最初の鉄道によるincomeは指数関数フェーズのどの位置から始まるかに当たるため、かなり重要。相応に大きな距離をつなぐのがよい(最大にこだわる必要はない)。複数の人をつなげられてたくさんincomeが得られるようならなおよし。
二次関数フェーズになってきたあたりから、最適化の価値は少しずつ薄くなっていく。基本的に計算リソースが足りないので、このあたりで被覆するような駅を決めてしまって接続のみを考えることで妥協してしまってよい。被覆は頂点数を基準にして、タイブレークとして(25,25)からの距離和を利用するとよさげ。最後の接続を考慮すると駅範囲がかぶっていたらその数にあわせて減点したいが、高速な方法がほしい。
今回のコンテスト方針を仮決定する。この順で実装を進めたい
・「序盤のビームサーチ」と「次数が高々4のグラフから線路を生成する」部分を作成し、線路生成が可能か、将来性を判定する。できたら提出。
・「頂点被覆の決定」を雑に焼きなましで実装し、ビジュアライザで頂点被覆をみる。あんまり焼けていなくてもまあ良い。
・「接続順の決定」(あるいは「木の生成」→「接続順の決定」)をビームサーチで決定する。貪欲がそこまで悪いとは思わないので、まずは幅は小さくてもよい。できたら提出。
・接続は途中で打ち切ったほうが良い可能性があるため、どこまで接続するかを評価する。ここまでを前半戦のうちに出せたらある程度上位になっているはずで、そうでなければ方針ミスを疑ったほうが良い。
その後の展望として
・雑実装部分を高速化する
・treeの形が決まったところで改めて最初からビームサーチをしてみる
・あらかじめ線路構築を見据えたtree作成
など。主方針を決めてからの改善の余地はかなり多いと思われる。
そういえば、グラフが平面的かどうかは特定の形をマイナーとして含むかどうかで判定できた気がするが、実用的ではなさそうか・・・?もっとも、形がある程度適切な形であれば、そういった考慮はそんなに必要なさそう。
もしかして、序盤のビームサーチでは今後を見据えた線路を作る必要がある?例えば、最初につなぐのがAからBだったとして、その次にCにつなぐ場合、AからCを経由してBがつなげられたらCにつなげるときに1手でいいので結果的に早くなりそう。ビームの状態の持ち方は要検討だが、ありそうな候補が多いなら焼いたほうが良いかも。
上の懸念は無視してビームサーチに解を作ってもらった。
9 47
3 9
14 48
18 10
6 42
5 33
1 6
10 43
24 8
31 0
の順にやると260~270手あたりでincome500を達成できるとプログラムは言っている。本当かはわからない。

いわれた順につないだら248手でincome500を達成した。これはかなり早そう。
問題は、言われた通りに線を引くところで、駅のどの方向から出すか・どこで曲がるかといったのは手で順番につないでいく際はわからず何回か修正することになった。計算リソースで殴るか・・・?学術的な話だとrectilinear embeddingというのがあったが、あれは確か頂点位置が固定されてないのでそこからさらに変換をかける必要があるというのはうれしくない。
話は戻ってビームのほうだが、結局ビームの深さはターン、評価はincomeをベースにしたものを採用する。長期的に見ると片側だけ抑えている状況も有効であるため、ポテンシャルと称してそれらの和をとっておく。実行時間超過だがseed=3で400万達成と言っているので実現すればうれしいが・・・。
2/16
予定のためほぼ不参加。
計画から実際の線を決定するところで、良い方法があまり思いつかない。chatGPTさんに初めてビジュアライザを生成してみてもらう。比較的拡大しやすいseed8での計画はこんな感じらしい。(数字は構築順)
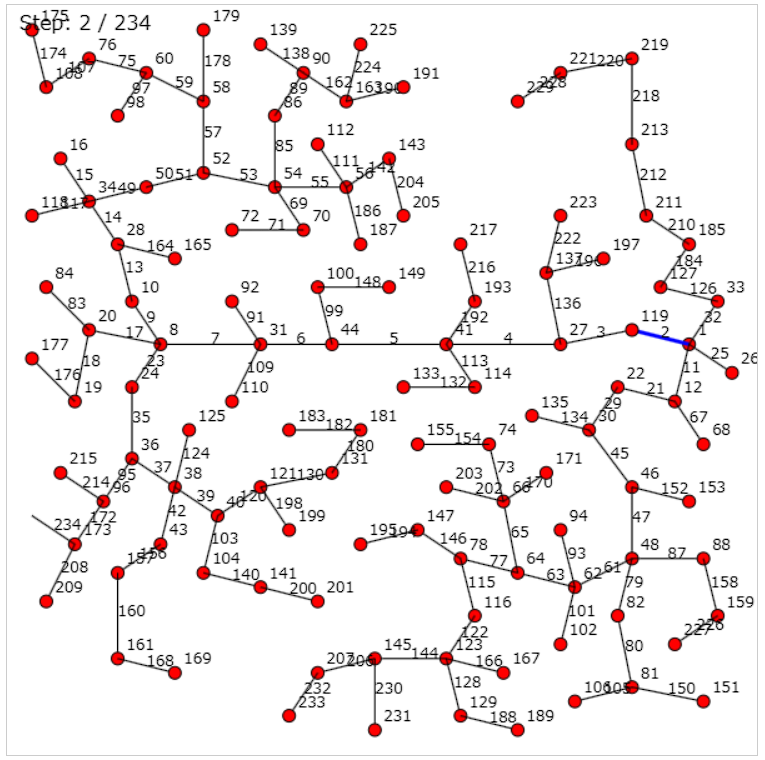
次数の制約やそのほかの性質もあってそんなに難しい形はしていなさそう。
しばらくは考察部分に変化なさそうで頑張って書く部分そうなので、何かあれば書いていく。
2/17
深夜に時間が取れたのでAHCをやっていく(2/18 0:00~6:00。2/17とは・・・?)。
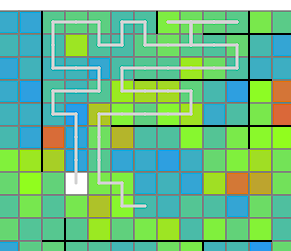
バグをかなり踏んでいるよう。ChatGPTに書いてもらったvisualizerがある程度線路の形を作ってくれていたので何回かお願いしてグリッド上に起こしてみてもらう。これを提出プログラムにねじ込む雑仕様で乗り切れるか。線路の分岐方向にある程度性質の良さがあれば、適宜簡単な再ルーティングを行うことで生成には成功するらしい。
2/18
ある程度incomeが増えると駅設置の律速が線路敷設になるため、途中から駅設置を待たずに次の駅に向けて敷設を始めるようにした。手元で見る限り5~10%位伸びるケースもあるみたい。incomeが爆発しないケースではほとんど伸びなかった。
一部のケースでうまく線路を構築できないみたい。ChatGPTの用意してくれた再ルーティングに問題がありそうだな・・・。
->再ルーティングが正しく実装されていませんでした
ほかにもChatGPT由来のバグがあるとしたら普通に手で書いたほうが最終的によかったかもしれない。
TLE祭りだが、REはなくなった。
![]()

提出前後の他の人の相対得点を見るとunique bestもあるみたいなので、解法のポテンシャル自体はまずまず。心配なのは、TLEが多く発生していると思われる人口大のケースで性能がどうなっているか・・・。ちょっと苦手そうではある。
手元で行う限りでは線路のルートを決めるときに稀に実行エラーが発生する(なんとなく理解している)ので、いつか直したい。
深夜4時、アクション試行順をソートして枝刈りすることで何とかTLEを6件まで減らすことに成功。+5.4G~+6Gと考えると悪くなくて、週明けぐらいに提出できていたら最上位陣に食いこめたくらいか。

今回の日記は問題の方針決め~前半の動きを残すものとして書いているので、このあたりで打ち切る。多分基本方針は変わらずバグフィックスや微改善が詰め込まれることになるだろう。線路のルート決めを成功させるために鉄道駅間の距離を一定以上にしているところあたりなどが改善の期待ポイントか。
最終日
久しぶりに日記に戻ってきた。以降基本方針は変わらなかった。(決して書くのが面倒だったわけでは)
被覆をあらかじめ決めるようなやり方はあまり効果がなく、序盤の展開用のビームサーチをそのまま800ターン使うことになった。(ビーム幅は2・・・)
被覆事前決定・途中決定方針がうまくいかなかった原因としては、
・(特に人口の多いマップでは)線路敷設数がネックになっており、いかに線路数を減らせるかが重要だったこと
・ペアの両方を被覆して初めてincomeになるため、うまくかみ合わなければ評価に現れづらく効果を発揮できなかったこと
・序盤の駅と終盤の駅の意味合いが大きく異なるものだったこと(前半のincome差はとても強く影響する)
などがあげられる。後ろ二つの点は単純な貪欲が得意としている方向性だったため、貪欲を上回るのにはおそらくかなりの焼きなまし能力が要求される。焼きなまし自体は十分あり得るため、焼きなまし得意勢のコンテスト後の解法ツイートが楽しみ。
AHC038でビームサーチをしてみよう!

(AHC038画像、GIFはAHC公式Visualizerよりお借りしています)
(上の出力は、最終的に出来たサンプルコードのものです!)
はじめに
初めまして(orお久しぶりです)。これはAHC038でビームサーチを打ってみよう!という記事です。ビームサーチを既にご存じな方には新しい情報はないかもしれませんが、ぜひ見ていってください。
コンテスト後の解法ツイートを眺めますと、「貪欲をある程度まで改善させてきたがビームサーチには手を付けられなかった」というお話をよく目にします。貪欲が高速で強ければビームサーチで化ける可能性もあるのではないかと思うので、ビームサーチをやったことがない・知らないという方にぜひ一度試してほしくてここに書き残しておきます。普段は半分自分の備忘録として書いていますが、今回は8割くらい「まだ試したことがない人に参考にしてほしい」というつもりで書いてます。
この記事では、言葉の厳密さや定義の厳密さといった部分は甘めに見ていただいて、気持ちを伝えられたらなと思っています。ここでは、感覚を伝える前半はコンテスト的でない抽象的な例を用いているため、今回のAHC038を知らずとも見やすい内容かと思います。後半の実際に組み立てるところでは、具体的な対象としてAHC038を用いています。
(執筆時点ではまだ行われていませんが、AHC038に対応するAHCラジオがあります。このラジオでは問題の解説や関連トピックが聞けるのでいつもお世話になっています。これを見てからAHC038でビームを打ってみるといいのかも?)
ビームサーチって?
ビームサーチは、
・保持している途中盤面を取得します。
・各盤面から有効な手をいくつも試し、それぞれ次段階の途中盤面として保存します
・次段階に進みます
というのが基本的な流れになります。貪欲法を、「盤面を一つだけ持っておき、その盤面から最も良い手を選択して新たな途中盤面として保存する」と考えると、ビームサーチは貪欲の延長戦のようにあるように見えるかと思います。
ところで、上の説明には「どこまで保存するか」という重要なところが抜けています(全部の盤面を保存するのでは、全探索になってしまいます)。こちらを説明するのに使われるのが以下の用語です。解法ツイートなどで流れてくることもあるんではないでしょうか。
- 盤面評価:途中盤面のよさを評価する値
- 深さ:初期盤面からの進み具合・段階
- ビーム幅:各「深さ」に対して保持しておく途中盤面の数
これらを用いて説明すると、「各深さで、盤面評価の高い順に、ビーム幅分だけ途中盤面を保存する」というのがビームサーチの方針です。ビーム幅1のビームサーチ=貪欲法になります。
なんと、ビームサーチの基本的な説明はこれで終わりです。
参考として、ビーム幅2のイメージを載せておきます。(左から右に行くほど深さが深くなっていき、上のものほど評価が高い盤面という扱いです)
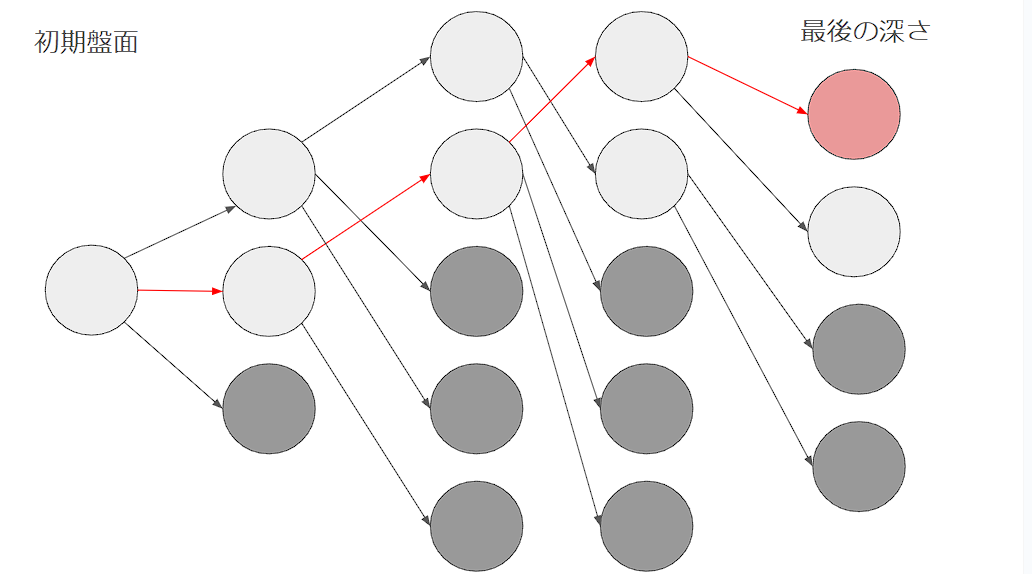
ビームサーチの強み
前章ではビームサーチの形を紹介しましたが、ここでは、例をもとに強みを考えてみます。
頓死のリスクがある場合に対応できる
ビームサーチは複数の盤面を候補として持っているため、一部の盤面で詰んでしまっても続行が可能です。とくに、「貪欲がかなりうまくいくがたまに地雷を踏んで大撃沈してしまうような問題」においてはビームサーチは最強格の方針になります。
例として、「ハイスピードなレースゲーム」が挙げられます。ハイスピードなレースゲームでは基本的にカーブの内側を攻めながら速度を可能な限り上げるのが最も速いですが、貪欲にカーブしようとすると次のカーブで耐えられずクラッシュしてしまう可能性があります。ビームサーチでは、ちょっと前にアクセルを外していた世界線や、事前に少し外側に膨らんでいた世界線などが有力候補として残っており、これらの生き残った世界線からまた分岐を繰り返すことで、また多様な有力候補が補充されます。
ビーム幅2でのイメージです。ここでは「欲張りすぎて次がない」として、「とれるアクションがない」という形にしていますが、「遷移先の評価値がめちゃくちゃ低い」というパターンもあります。

手の評価を雑にできる
貪欲法では、複数の盤面を持てないために一手一手を外さないように慎重に評価する必要があります。例として、前述の例では大撃沈を防ぐために、先読みを含むような複雑な評価指標が考えられます。一方でビームサーチではよさげな盤面のうちどれかが当たれば大きな問題はないため、ふんわりとよさそう・よくなさそうを評価できれば十分強力になります。
ビームサーチの深さ・盤面評価
これはビームサーチをするうえで一番難しいところかと思います。実際、明確な正解が一通りに決まっているわけではなく、「深さ・盤面評価のかみ合わせ」が良いものをとってくるというものになります。ここでは、二つの組み合わせパターンを紹介します。
深さ:時間・コスト, 盤面評価: 進捗
このパターンは、時間・コストとして整数のものがとってこれる場合に使用可能です。
深さ:進捗, 盤面評価: 時間・コスト
このパターンは進捗として整数のものがとってこれる場合に使用可能です。
結局、進捗と時間・コストはどちらも少なくとも小数で表現しておく必要があるので、近い整数に丸め込んだり、数字をn倍したりでどちらでも対応できなくはないです。ただ、向いているのがどちらかというのはあり、基本的に深さ側は
- 行動を行うごとに最低1増えるもの
- 値がある程度小さいもの(10^5とか言われるときついです)
- 同じ深さ同士で状態の良さの比較がしやすいもの
であるとよいです。ビームサーチの以下の特性がそれぞれに対応しています。
- 「ある深さのすべての候補盤面から有効な手を試して次の深さに進む」を繰り返すアルゴリズムであるため、深さを逆戻りや停滞は基本許されない
- 各深さでビーム幅分状態を保存することになるので、手を試す回数は(深さ)×(幅)×(各盤面から試したい手数)となる
- 各深さでは上位ビーム幅分のよさげな盤面を保持する
特に、行動を行うごとに1増えるようなもの(つまり行動数)が非常に都合がよいので、そのうえで深さが上の条件を満たすように「行動」の概念を考えることがほとんどです。(少なくとも初めてのビームサーチではこのタイプのものを強くお勧めします)
深さが1ずつ増えるとは限らないようなビームサーチはこんな感じです。(煩雑になるのに対して、より適切な深さの定義で行ったほうがパフォーマンスが高いことも多いため、特に強い理由がないときは選ばないほうが無難です)

AHCで実際にビームを打つ
ここまでは具体的な話をせずに説明をしてきましたが、「実際のところどう実装するの?」というのが一番の疑問点かと思います。ここでは、AHC038においてビームを打ってみます。サンプルコード(Go言語)にかなり多めに説明を入れるため、AHC038にすでに何らかの形で解を出した方なら他言語の方でも内容を見つつビームが打てるんではないかと思います。
前章までの内容を前提として用意しているので、適宜読み返していただけると。
1.ビームの深さ・評価関数を決める
今回は「アームを操作した回数」というものが深さの条件にぴったりな気がします。アームの操作がそのまま最小化したい対象になるので、あとは同じ深さ内で、「どれだけ進捗が進んでいるか」をもとに盤面を評価・比較したいです
対応する盤面評価は少し検討が必要です。ぱっと二つ思いつくかなと思います。
- 「M個のたこ焼きを拾い、M個のたこ焼きを置く問題」とみたとき、2M段階の進捗のうちどこまで進んでいるか
- 「M個のたこ焼きを正しい位置まで動かす問題」とみたとき、あと合計何マス移動する必要があるか」
私が採用したのは前者でした。いくつか理由がありますが、どちらかというと後者に難しさがあり、具体的には以下のような部分が懸念点として考えられました。
・定義の仕方によっては、M個のマッチングで距離総和を最小化する問題などとみることができるが、それ自体が時間のかかる問題であるため、近似する代替のものが必要である
・木の回転は遠くの距離を一気に移動できる操作であり、どのたこ焼きをどこへ運ぶかは距離が近さよりは木の形とのかみ合わせのほうの影響を受ける
2.木の形を考える
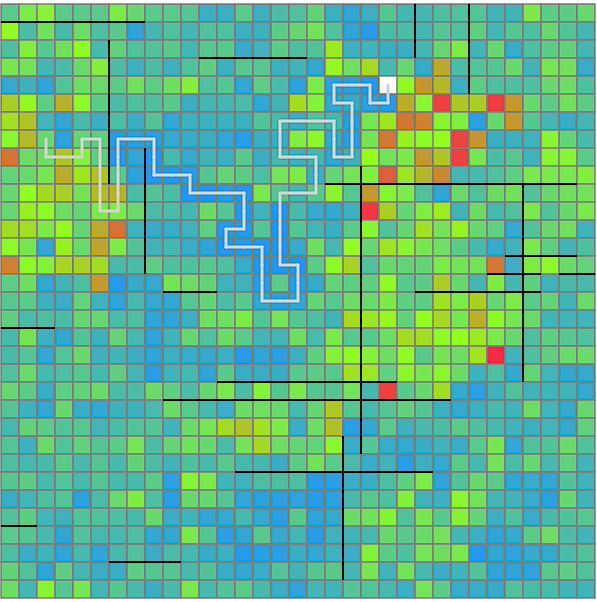
たこ焼きを運ぶ最中に木の形は変更できないので、最初に決めてしまいましょう。最終的に適切な木を選定するところが大事になってきますが、今回は妥当な木でビームを打ちたいだけなので、

この図の一番左の木を採用します。この形になった経緯は割愛しますが、箒型には以下のような利点があります。
- かたまったエリアのものをまとめて拾う・置くことができる
- 箒の柄?の部分の回転の組み合わせで、遠くのいろいろな候補へ移動させられる
3.盤面の保持の仕方を考える
行動によって変動する部分のデータ
通常のビームサーチでは、盤面を何度もコピーすることになるので可能な限り情報をコンパクトにしたほうが良いです。ここでは天下り式に与えますが、操作を行うごとに変動する部分は
・根の座標 長さ2の配列
・各頂点の相対的な回転角 長さVの配列
・各頂点がたこ焼きを持っている状態か 長さVの配列
・各マスにたこ焼きがあるか 長さN,Nの二次元配列
・累計操作回数 整数
・(進捗 整数or小数)
になります。これをひとまとめにして構造体にします。私はなぜかこれをGameStateと名付けてます。
行動を試す間変動しない部分は別の構造体で保存しておきます。
木のデータ
木のデータは
・葉じゃない頂点の数 整数
・各頂点の親の頂点番号 長さVの配列
・各頂点の長さ 長さVの配列
で表現できます。
木以外の変わらないデータ
ここには入力で受け取ったものを(必要に応じて加工して)保存しておきます。
記載漏れもあるかもしれませんが、おおよそ以下が固定情報になります。
・たこ焼きの目標配置 長さN,Nの二次元配列
・たこ焼きの初期配置 長さN,Nの二次元配列
・たこ焼きの数 整数
・盤面のサイズ 整数
・使える頂点数 整数
4.気合で書く
もう方針は立ちましたので、あとは書くだけです。最初は気が滅入る実装作業ですが、手を動かしてみたら意外と早く終わることもあります。ので、気合で完成させます。(今回、この記事に合わせて再走しました・・・)
ここにAHC038におけるGo言語でのサンプルコードを載せておきます。TryPossibleActions()が途中盤面に対して候補手を列挙している部分になります。
(気になるところから見てもいいですが、main関数から順に使われている関数を見ていくと理解しやすいと思います)
Submission #58872607 - Toyota Programming Contest 2024#10(AtCoder Heuristic Contest 038)
![]()

高速化の工夫などはほとんど入れていないため8件TLEが発生していますが、そのうえで延長戦順位表において31G(71位)を達成しています。本番だとこの時点で黄パフォになります!
ぜひ、ここを起点に自分だけのビームサーチを考えていってください!
今後の改善方針
とはいえ、ここでいきなり投げるのもどうかと思うので、改善方針を書いておきます。
まず前提として、8件もTLEしてしまっています。これだけで8G失っているのは非常に痛いので、この解消を目指すと効果的だと思います。そのうえで、ビームサーチの典型的な改善方向としては
- 高速にすることでビームの幅を増やす
- 盤面の評価や多様性の確保によりより好ましい途中盤面たちを保存する
- 各盤面での候補手として、もっと良いものを採用する
が挙げられます。今回の問題ではこのほかに
- 木をもっと良い形にして効率的にたこ焼きを運ぶ
というのもあるかと思います。
実際にTLEをなくす
「よくわからんがとりあえず成功例を見て次につなげたい」という方のために、ここで実際に直します。
goのpprofでどこで時間がかかっているか確認すると、

ボトルネックについては使用言語や個人の実装方法依存するので一概に言えませんが、TLEしているコードでは、TakoyakiPlateの上書きやTakoyakiPlateの配列確保に時間をかけています。また、その源流がGameState(状態を格納する構造体)のコピーであることも上図からわかります。GameStateのコピーは有効手を検討するたびに発生しているので、時間をとっているのももっともですね。
ここでは以下の改善をします。(割と今回の問題に限らず色々なコンテストで似たような改善ができます)
- 葉の回転方向を決めたときに拾う数・置く数がわかるので行動を実行する前に評価値を計算し、見込みがないなら試さない(より賢い変更としては、Action、どのpossibleStateに対して適用するか、評価値の三つだけをqueueに突っ込み、最終的に上位になったものだけgameStateをコピーして実行するというのがあります)
- 各要素1bitでデータを表すことでTakoyakiPlateをN,Nの二次元配列ではなくNの配列に抑える
逆に時間に余裕が出てきそうなのでビームの幅を300にしてしまいます。(言語、実装によります)
(コードは以下。エディターで差分が見れる人はエディタにコピーして確認したほうがいいかも)
Submission #58876594 - Toyota Programming Contest 2024#10(AtCoder Heuristic Contest 038)
これを提出すると・・・
![]()

延長戦で39G(46位)になります!本番で提出していたら2300くらいのパフォーマンスが出ます。
実際に改善を入れる
「よくわからんがとりあえず成功例を見て次につなげたい」という方のために、ここで改善も一つだけ試してみます。
TLEをなくした後のプログラムの出力を見るとこんな感じの動きをしています。
(seed=2)
3つの葉をかなり限界まで利用していて、とても効率がよさそうです。
一方で気になるのが、最後の10~20手ほどです。空きマスが少なくなってきたということもあり狙ったところへ入れる必要が出てきますが、アームの長さの限界もあるため、最後の数個は特に入れるのに苦労している印象を受けます。ここで、これに対する解決策として候補手の選び方、盤面評価の部分で以下の工夫を入れます。
- 葉の回転を決めるときに、できるだけ中心から遠いものをとってくる
- 進捗が同じもののうちでは、これまでとってきた・置いてきたたこ焼きについての中心から総和が大きいものがよいとする
葉の回転の工夫については、decideGreedily()内で3方向すべて試すことで、たこ焼きの評価値については、GameStateにBonusValueという変数を追加してActionを適用するごとに足すことで対応します。
もちろん乱数次第ではありますが、seed=2が91手から83手になりました!
最終提出の自分のプログラムがだいたい79~81手なのでかなり良い結果です。
実際に提出してみます。(コードは以下)
Submission #58878428 - Toyota Programming Contest 2024#10(AtCoder Heuristic Contest 038)
![]()

(乱数でTLEしたりしなかったりしますが)見事延長戦で40G(40位)になり、橙パフォーマンスまであと0.5Gほどまで来ました。これに何か改善を加えて橙パフォといったところです。本番は一週間以上ありますので、実装が苦手でも頑張れば(生活を破壊すれば)ここまで順位表を登れる気がしてきませんか?
(自分の最終提出(最終3位)はこの延長線上にあるので、ぜひさらに伸ばしていただけると・・・!)
終わりに
今回は通常のコンテスト後のPostMortemに代わりビームサーチ入門記事を書いてみました!といいつつ、自分の解法の核の部分は説明できたので実質PostMortemになってるかも?
問題について。問題文を読んだ時の絶望から一転、ビームサーチを書いてみると人知を超えた動きを軽々とやってのけてくれて、出力を見るのがとても楽しい問題でした!毎度面白い問題を用意してくださりありがとうございます!
ここまで読んでくれた方に向けて。かなり長めの記事になってしまいましたが、読んでいただきありがとうございます!「一度成功体験を積む」というのがコンテストの結果を伸ばすにあたってかなり重要だと思っているので、この記事で成功体験を積んでもらえればと思います!(参考にして結果が出せたらぜひ報告していただけると筆者が喜びます)
長期AHCでの時間配分
はじめに
皆さん初めまして(お久しぶりです)。この記事では自身の長期AHCにおける時間配分について書き連ねています。なお、この内容が参考になるかといえばかなり怪しいので、その点についてはあらかじめ断っておきます。
前記事というのはこちら。こちらのほうがまだ参考にできる可能性が高いです。
長期AHCの流れ
以下は自分の場合の例であり、他の人にとって適切な流れはもちろん違うことに注意されたい。
(おそらく、ほかの方の参加期やツイートを見るに自分の時間配分はだいぶ「実装力<分析力」型っぽい)
もちろん、24時間AHCをやっているわけではないので、期間の表記はかなりゆるく見てほしい。
問題読み込み期(1日)
AHC序盤の問題読み込みタイム。長期AHCは問題の内容を頭の中でかみ砕く必要があり、それなりに時間がかかる。ここで問題を勘違いしたまま考察に入るとかなり引きずるので少し慎重に。最後に、問題で基本となりそうな(とても)単純な解を確認テストとして提出する。たまにここで楽しくなって単純な解を改造して再提出したりするが、雰囲気がわかればいったん理性でこらえる。
解法検討期(1~4日)
AHCの問題を無事理解したら、解法の検討に入る。長期AHCの問題はシンプルな定式化でそのまま良い解が得られるような問題ではないことがほとんどなので、問題の捉えなおしを何回も行う。とらえなおして解法を考えるたびに、解法の将来性などを考えて棄却する。解法に関する自分の感覚云々については気になる方は前記事へ。コンテストに出るたびにこのあたりの引き出しが増えることで安定してきてそう。
コンテスト外での話として、このタイミングでコンテスト終盤に期限のあるタスクは済ませておくとよい(諸手続きや買い出し、料理の作り置きなど)。この期間は日常生活中にも頭に居座ることがあり厄介であるが、逆に日常のいろいろな場面で考えることができるとひらめきも多い気がする。
重実装逃避期(2~7日)
コンテスト中で最もいらない時期(日数は現実逃避日込み)。解法を思いついてうまくいきそうなことまで確認できたのは良いとしても、プログラムを書き始めるときに非常に大きなエネルギーを要する。実装が重いとこの必要エネルギーも大きく、エネルギーが足りず撃沈した回もある。不思議なことに、完成した後に振り返ると「これくらいならもっと早く書いておけばよかった」となることが多い。この段階で完成させるつもりはなくて、ここでは解法の芯を作るようなイメージ。(今後の自分へ:ここでパラメータ調整してあそぶとかはやめてね)
バグ修正&成長期(2~4日)
一番楽しいとき。バグは楽しくないが、重実装逃避期にゆっくり気を付けながらやってもらうとあまりバグらなくなる(経験が増えて慣れてきた説もある)。ここからの改善パートは発案→実装がこれ以前に比べ圧倒的に短く何サイクルも行えるので、順調に点が伸びる。最初はバグ回避のためやらなかった高速化などを入れられると世界が変わることも。
限界期(1~3日)
パラメータもある程度適切になって工夫点ももう見つからなくなってしまった状態。あるいは、いろいろ思いついたがいざ試してみるとどれも改善しなくて自分の解法がある種局所最適に陥っている状態。かなり苦しい。マラソンの最後なので大きな変更案を試せないというのも原因としてありそう。
短期コンの場合これらの所要時間を短期コンの期間に合わせてスケールしてもあまりうまくいかない。実装速度によるが、短期コンはもっとも筋が良い解法を吟味していると時間が足りなくなりがちなので、ある程度自信が持てたら実装してしまったほうが良い気がする。最後の限界期も自分の実装速度が5倍くらいにでもならない限り訪れないと思う。
解法選択・改善のパターン
流れとはちょっと違う話になるが、AHCへの解法選択・改善にはいくつかの型があるように思われる。これらにはそれぞれ得意とするところ、苦手とするところがあるので、自分の特性にあわせて組み合わせられるといいかも?
以下もすべて自分の所感なので異論は認める。
山登り型
簡単な解法を試した後に、評価関数を変更したり新しい要素を加えたりして、平均的によくなっていれば採用するパターン。基本的なやつ。
メリット
・改善の労力が小さい・改善にかかる時間が短い
デメリット
・低いところで解法が頭打ちになりやすい
この型に向いている人
・AHCの経験がまだ少ない人
・早い段階から順位表に乗りたい人
以下の二つの型は上の山登り型より良いように思われる。この二つについてのメリット・デメリットは他方と比較して書いている。
複数実装型
複数の解法・改善案を考え、それらの簡単な実装を行い、結果からどれが良いかを見極めるパターン。
メリット
・要求される考察が少なめ
・「一見厳しそうだが実は良い解法」を発掘しやすい
デメリット
・コード記述量が多め
・バグから誤った直感を得る危険性がある
この型に向いている人
・実装速度に自信のある人
・実装の精度に自信のある人
事前組み立て型
複数の解法・改善案を考え、それらの良さを見積もることで実装する前から解法・改善の方向性を決めるパターン。
メリット
・コード記述量が少なめ
・バグから誤った直感を得る危険性が低い
デメリット
・要求される考察が多め
・「一見厳しそうだが実は良い解法」を発掘しにくい
この型に向いている人
・問題の考察をするのが好きな人
・自分の考察の正確さに自信がある人
自分の場合は、途中までは事前組み立て型で終盤の限界期は山登り型だったりします。
過去のAHCでの配分
ここから下はほぼほぼ自身の振り返りです。
過去のコンテストの提出記録・githubの履歴から自身の時間配分と結果の振り返りを行う。
AHC014
これは長期コンの中でも長いタイプのコンテスト。調べてみた結果
・問題読み込み期(4日)←このタイミングで現実逃避してた
・解法検討期&重実装逃避期(並行で2日)
・バグ修正&成長期(1日)
・限界期(7日)
コンテスト終了後までバグが残っていたりずっと限界を感じていたりと散々である。解法の吟味の前に実装を始めてしまい、その後パラメータチューニングまで軽く済ませてしまっために別解法へ行けなかったようだ。このときはどちらかというと山登り型だったかも?
AHC016
調べてみた結果
・問題読み込み期(1日)
・解法検討期(3日)
・重実装逃避期(0日)
・バグ修正&成長期(3日)
・限界期(2日)
といった具合。なんか重実装自体を避ける結論になってた。このころは精力的に参加期を書いて振り返っていたのでAHC014の反省を生かして軽実装の当たり方針を3日検討してます。最初の読み込み期では、何回かサンプルプログラムを改変して提出していて、後のいい考察につなげられていそう。このときもどちらかというと山登り型だったかも?
最終的な順位は前より上がっているわけではないものの、この問題に関しては知識不足だったことを考えると良い流れ。
AHC018
調べてみた結果
・問題読み込み期(1日)
・解法検討期(1日)
・重実装逃避期(3日)
・バグ修正&成長期(3日)
・限界期(1日)
といった具合。ちょっと解法検討が短そう。たしか「マップが広すぎるので縮小して扱おう!」みたいな発想だったと思うんですが、たぶん妥当性のことあんまり考えてないです。実装してみたら当たっていたという感じのコンテストで、ちょっと危険な思考だった気も。基本の実装が終わってから「掘る」というアクションの強さについて考察を始めていて、これが検討期にできていればもう少し安心して渡れた橋かもしれない。
結果は当時自己最高パフォで、うれしかった記憶があります。
AHC023
調べてみた結果
・問題読み込み期(1日)
・解法検討期(2日)
・重実装逃避期(3日)
・バグ修正&成長期(--)
・限界期(--)
といった具合。結果は前よりも良くなかった。解法検討期に良い解法が思いつかなかったことも大きいが、解法検討・重実装逃避期が長引いた結果妥協案の小手先改善が採用されてしまった点が決定的だったかもしれない。重実装逃避はほどほどに、早めに取り掛かろうね・・・。
AHC025
調べてみた結果
・問題読み込み期(1日)
・解法検討期(1日)
・重実装逃避期(1日)
・バグ修正&成長期(5日)
・限界期(1日)
といった具合。解法検討期に熟考して「これだ!」と思う解法がすぐ思いついたのと、その裏付けが考えられたので安心して書くことができた。実装が小分けにできたので、段階的に実装していくことで重実装逃避期を回避できたのもよかった。今後、実装をより段階的にできないかは考えてみてもいいのかも?
AHC027
調べてみた結果
・問題読み込み期(1日)
・解法検討期(3日)
・重実装逃避期(--日)
・バグ修正&成長期(1日)
・限界期(4日)
といった具合。焼きなまし想定の回に貪欲で取り組んだ新鮮な回。焼きなましを十分高速・効果的に行う方法を模索していて検討期が少し長め。最終的に難しいという結論に至り貪欲を使うという結果に。理想な形についての考察であったり、貪欲の過去改変であったりと貪欲法でも戦えるようにするための構想を検討期に考えておいたことにより結果は悪くなかった。コンテスト後に明らかになったことではあるが、実際焼きなましの難度はかなり高く、焼きなましで成功していた参加者はかなり限られていた。
AHC029
中期(?)コンなので日数で書くほど期間はなかった。実装は確か初日から始めているので、あえて書くなら
・問題読み込み期・解法検討期(1日)
・重実装逃避期(2日)
・バグ修正&成長期(2日)
・限界期(--日)
といった具合。期間の短さの割に成功できたのは、問題を見た段階でモンテカルロ法でほぼ決まりだと感じて貪欲を利用したプレイアウトの方針が一瞬で決まったことが大きいと思う。モンテカルロ法は実装経験が少なく、コンテスト終了まで改善を続けることができた。今後実装経験を増やしていくとこのあたりの改善スピードが速くなって期間内に取り組める内容が増えるのかな・・・?
以下はまだ書けてないです
AHC030
AHC031
AHC033
さいごに
これだけ書いておいてなんですが、この部分はかなり個人個人の特性によるところな気がします。(人によっては検討期が苦痛で実装のほうが手を付けやすいという話も聞いたことがある)
あくまで、「長期AHCの1参加者がこんな感じで取り組んでいるんだなあ」という風にとらえていただけると幸いです。(自分が中盤に上位にいたら重実装じゃなさそうくらいの人読みができるかも?実際そういう場合があればかなり軽い実装の時or別人だと思います)
AHCでの解法選択
音声概要
更新:2025/05/30
notebooklmというのを利用し音声概要を作ってみました。面白かったので追加しておきます。
はじめに
この記事はAtCoderで不定期に開催されているAHCにおける問題の性質別の自分の解法の選択について述べたものです。自分の場合、基本的に短期、長期のいずれも解法の大方針を変えることはほとんどなく、最初に問題をじっくり見つめて吟味したものが採用されています(短期については、二つ以上の方針を書けるほどの実装力がないことが主な理由で、長期については、時間を全投資すればそれなりの精度で吟味する時間が与えられていることが主な理由です)。ここ一年くらいはこの解法選択の直感が昔に比べて成長していると感じていて、一度今の自分の考えをまとめたいということでこの記事を書いています。先に述べたのがこの記事のモチベーションの7割くらいですが、この内容が参考になる方、より良い考えを教えてくれる方がいればと思い公開しています。
この文章では焼きなまし、ビームサーチなどの詳しい説明は行いません。「自分が取りうる解法」で解法選択において大事になりそうなイメージを述べているので、その項の内容だけで以降の内容についていけるかもしれないですし、ならないかもしれないです。すみません。
(自分が学び始めたころ、世の中の解法の記事はどれもかなり難しい印象をもっていたので、いつか、初めて○○に挑戦したい・一回○○を実装してみたけど思う結果にならなかったという方に向けた簡単な記事を書けたらと思っていますが・・・)
気を付けてはいるのですがところどころうっかり打ち間違っているかもしれません。間違いを発見されましたら優しく教えていただけるとありがたいです。
自分の考えをまとめたものであるため、以下では敬語は省略しています。
注意:以下、それなりに長いです
自分が取りうる解法
AHCでよく使う
・山登り
おなじみのやつ。暫定bestの解の一部を変えて別の解を作る。よくなってたら新しいほうの解を今のbestとして時間いっぱい繰り返す。
・焼きなまし
おなじみのやつ2。暫定bestの解の一部を変えて別の解を作る。山登りと違ってよくなくても確率で採用する。「よくない」の度合いがひどいほどで採用する確率を下げる。
・ビームサーチ
おなじみのやつ3。主に「ターン」の概念が用意できる問題において、ターンのそろっている有力セーブデータを何個かキープしておいて、各有力セーブデータでいろんなパターンで1ターンずつ進めてみる。(で、その1ターン進んだセーブデータのうち有力なものをいくつかキープ)
・モンテカルロ法
おなじみとまではいかないかもしれないやつ。有力な選択肢に対して、その選択を選んだあと最終的に(あるいは数ターン後)スコアがどうなるかをシミューレーションしてみて、最も良いものを選ぶ。(この手法はたいてい確率でどうのこうのみたいな要素があるのでシミュレーションはたくさんやってスコアの平均(たまに平均じゃないこともある)をとる)
・貪欲+破壊再構築(山登りの一種)
なんかのルールで貪欲に解を決める。そこから一部を破壊(設置系の問題なら「一部のアイテムを取り除く」、ルートを決める問題なら「一部のルートを未定にする」など)して、破壊した部分を貪欲で決めなおす。よくなってたら採用。
もちろん、問題の全体の方針として使うこともあれば、問題の一部に注目してその部分を解くのに使うこともある。
AHCではあんま使ってない
・MCTS
自分は今のところ有効に使えてないので略。
・機械学習
これはコンテストによっては主方針として十分強力なこともありそうだが、なんの知見を持っていないので「なんかこの問題機械学習が使えそうだな~」といいつつ実際に使えるかどうか全然わからない。ので略。
問題の性質と向き不向き
この項を読む方へ
ここでは問題が持つ諸性質について、山登り、焼きなまし、ビームサーチ、モンテカルロ法が向いているかどうかの感覚が述べられている。もっとも重要なこととして、「執筆当時の私が思う」向き不向きで、各解法について、人それぞれにまた違う印象を持ちうることに注意されたい。すべてに「~と今の私は思っている」と続いていると考えてほしい。
上で述べた4つの解法(山登り、焼きなまし、ビームサーチ、モンテカルロ法)について、向き不向きを+3~-3で評価し、各見出しに(-1,+3,-2, 0)などと解法順に表記する。評価方法にはブレがあるが、おおよそ以下の通り。
・+3 この性質があると非常に扱いやすくなる / この性質がないと致命的に扱いにくい
・+2 この性質があるとまあまあ扱いやすくなる / この性質がないとまあまあ扱いにくい
・+1 この性質はないよりはあったほうが良い / たいていはプラスに働く気がする
・ 0 プラス要素とマイナス要素がありどちらともいえない / この性質はこの解法に影響を及ぼさない
・-1 この性質はあるよりはないほうが良い / たいていはマイナスに働く気がする
・-2 この性質があるとまあまあ扱いにくくなる / この性質がなければとまあまあ扱いやすい
・-3 この性質があると致命的に扱いにくい / この性質がないと非常に扱いやすい
・-- 自分の中での感覚が定まっていない /わからない
考える問題は各性質をもってたりもってなかったりするので、その総合評価で主解法を決定している。部分的な問題に区切れば別解法が使えたりもするのでそれも検討する。
最後の総合評価は自分の特性(各解法の実装経験量など)で多少ゆがめている気がする。(執筆時の自分の場合、焼きなましは定数倍高速化がうまくできておらず、ビームサーチもまた状態コピーなどのコストをカットできていないため、山登りが少し選ばれやすいように思う。山登りからなら焼きなましに切り替えられることもあるし・・。)
重要性質
なんとなくここは各解法が欲している基本的な性質を書いている。問題がこの性質を含んでいるか?というよりはこの性質を持つ(あるいは持たない)ような問題の見方ができるか?というのを考えるほうが多いかもしれない。
問題にランダム要素が含まれる(-3,-3,-3,+3)
問題に乱数を使ったランダム要素・不確定要素があり、その要素の効果が表れる直前まで乱数の結果を知らされない場合。カードゲームのドローがこの代表的なものにあたる。これはモンテカルロ法についてはほぼ必須といってよい条件で、不確定要素のないような問題ではモンテカルロ法は他3つの劣化版となってしまうのがオチ。ランダム要素がないならモンテカルロ法はいったん忘れてもよい。逆にランダム要素がある場合、焼きなまし、ビームサーチが用いられるのは例外を述べたほうが早い。
例外というのは、
・不確定要素の数値的な影響があまりに小さい
(「あるカードを引いたらスコアに0.001点加点する」みたいな)
・確率分布などの統計量を見ることで不確定要素の効果が十分見積もれる場合
(ただ、例えばカードゲームの場合はこのターンで各カードを引く確率が計算できても、「その後このカードを使うとこの特殊効果が発動して次のドローは2枚になって・・・」など、最終的なスコアへの寄与は極めて難解であることが多い)
・たくさんのサンプル(パラレルワールド的なやつ)を持っておくことでごまかせる場合
などである。なお、すでに確定している部分と矛盾しない乱数結果を考えるのが難しい場合は、モンテカルロ法も難しい。
解の一部を変えて新しい解を作ることができる(+3,+3,+1, 0)
説明:このプロセスは山登り・焼きなましにおいて不可欠なもの。以下説明では遷移と呼ぶこともある。
ビームサーチにおいては、この性質があれば状態をコピーしなくてよいパターンになる可能性がある。(結局その実装の経験はない)
例:「5桁の数字」という条件でなるべく大きな数字を求めるような問題。
46378という解に対して、「ある桁の数字を変える」という操作で43378, 56378などの新しい解を作ることができる。
遷移が細かい(+1,+2, 0, 0)
説明:この遷移が解のごく一部を変えるようなものである場合。これは焼きなましによっていい感じの解へと流れていきやすい。山登りにおいてもうれしいものの、山登りは局所解を求める特性上遷移が大きくてもあまり問題にならない印象がある。
遷移の計算が高速(+2,+3,+1, 0)
説明:山登りに比べて焼きなましは悪くなる変化も採用するという仕様の都合で、考える規模と比べて十分に高速なら焼きなまし、そうでないなら山登りに軍配が上がる。同解法焼きなましバトルでは遷移の計算量が異なるとほぼ確実に敗北なので、定数倍高速化の差くらいには押さえておきたいところ。(というくらいに影響度が高い)
遷移の「逆遷移」が用意できる( +1,+2,+1, 0)
説明:これは盲点だったが、逆遷移のない焼きなまし場合、焼きなましの性能が保証できない。例えば「整数」という条件で数字を最小化するような問題を考える。極端だが遷移として「数字を+0~+6する」とすると、いくら遷移を繰り返しても確率での採用があるたび数字が大きくなってしまう。山登りでは、ある遷移が採用されたらたいてい逆遷移は採用されないのでここまで大きな問題にはならないが、評価値が変わらないものを採用するかによっては大きく影響を受ける。
ビームサーチにおいては、この性質があれば状態をコピーしなくてよいパターンになる可能性が高まる。
今の例題では逆遷移が用意できて、遷移を「数字を-6~+6する」とすると、期待の結果になる。BがAに近い⇔AがBに近いみたいな「距離」の拡張の気持ちで考えるといいのかも。
遷移を繰り返し採用すれば好きな解から好きな解へ移動できる( 0, +1, 0, 0)
説明:盲点2。この性質があるなら、焼きなましは時間をかけることで最適解を見つけられるのでこの性質がプラスにはたらく。問題の規模が大きかったり、到達できる解のうちに十分最適解に近い値が出せるものがあるならあんまり気にしなくてよかったりする。山登りでは結局局所解で止まるのでその部分が効くことは少ない。
例:「5桁の数字」の例では、5回遷移を繰り返すことで数字を好きな数字に変えることができる。
解を構成している途中段階が書けて、その途中段階に評価を与えることができる( 0,+1,+3,+2)
説明:解ではないが、解の作りかけのような状態が作れる場合。ビームサーチにおいては、この作りかけの状態の評価が不可欠。解の作りかけ自体は発想次第で無理やり作れるが、その途中段階に評価(最終結果の妥当な見積もり)が与えられるかが肝。モンテカルロ法においては、シミュレーションを最後までやらずに評価を与えられるので良い結果が期待できる。焼きなましにおいても、この途中段階を利用することで一時的にValidでない解に遷移できることがある。
例:レースゲームの運転を考える。最速で一周回ることを目的とすると、途中まで走っている状態で、経過時間と残り距離からおおよそ妥当な評価を与えることができる。
途中段階の「段階」を数値化することができる( 0, 0,+2,+1)
説明:ビームサーチは各有力候補の進み具合は揃えられたほうが圧倒的に良い。進んでるものと進んでないものを比べるのは評価の公平性を失う可能性がある。すべてを見通した「神の評価」があるなら気にしなくてよい。あるいは十分それに近い評価があるならごまかせるかもしれない。この数値化は整数であって1ずつ上がるもので最大値があまり大きすぎないものがうれしい。
例:レースゲームにおけるチェックポイント通過数.は進み具合を示す指標になる。
途中段階の「段階」を進めるような操作が書ける( 0, 0,+3,+1)
説明:ビームサーチで「1ターン進める」というのはこの操作のこと。これがないとビームサーチはできない。なお、その操作がコードで書ける(かつそんなに計算が重くない)というのは大事。
例:レースゲームにおいて「次のチェックポイントまで進む」という操作は段階を進めているといえる。段階を1だけ進める必要はなく、いくつか段階を飛ばすものも一応対応可能。「しばらくここで止まる」という操作も試したいようなら、時間など何らかの別の指標が欲しい。
主な性質にかかわってくる性質
解の要素がくっついている(-2,-2, -1, 0)
説明:Validな解の条件に解の要素同士をくっつけるような要素がある状態。Validな解を作るために他の要素を考慮しなければならず、山登り・焼きなましにおいては一要素だけを変更するような遷移が難しい場合がある(焼きなましにおいては一時的にValidでない解を許すという回避策がある)。この性質は問題自体を難しくさせているので、どの解法でもある程度困ることではあるが、ビームサーチは評価時の見積もりにうまく組み込める可能性があるので比較的その影響が少ないと思う。
例:「5桁の数字」という条件に「各桁の数字は(隣の桁の数字-1)か(隣の桁の数字+1)」という条件を追加した状態で、なるべく大きな数字を考える(最適解は98989である)。98765という解から一桁だけ変えて新しい解を作ろうとした場合、制約から8,7,6の部分を変えることはできず、かなり動かしづらい印象を受ける。また、この遷移では最適解に到達できるとは限らず、89898から98989へは何度遷移を繰り返しても到達できなかったりする。
解の要素に順序関係がある( 0, 0,+1, 0)
説明:問題が何かの順番を出力ものである場合。この性質単体ならあまり気になるものではなく、ビームサーチが手を付けやすいかもしれない程度。後述のより進んだ性質がいろいろ悪さしてくることがあるので注意。
例:「5桁の数字」でなるべく大きな数字を答える問題を考える。これを5個の数字を並べる問題ととらえると、桁は場所に意味があるので順序関係がある。
積み木ものせる順番を考えると順序関係になっている。
順序が異なると制約を満たさない(-2,-3, 0, 0)
説明:順番に依存した制約条件が課せられている場合は、「順番を入れ替える」というような単純な遷移が書きにくくなることで焼きなましが難しくなる。山登りは比較的大きな遷移を採用できるのでまだ影響は小さい。これは程度問題で、致命的にならないこともある。
例:積み木は、のせる順番が変わるとのらないことがある。積み木のセットによっては「三角の山の上に四角」など無茶なものばかりになる可能性もある。
グリッド上での移動方向列(→↑→↓→)なども、入れ替えると盤内の障害物に当たったりする。迷路のように入り組んでいなければ、入れ替えが成功することも多い。
前で述べた「5桁の数字」問題は、順序関係に関連した制約がないのでそういった心配はない。
順序が異なると結果が大きく異なる( 0, 0,+1, 0)
説明:二つの順番が逆になるだけで結果が大きく異なる場合。この場合はビームサーチで「順番が違うけど結果的に似たような状態」というのが発生しにくく、有力候補がすべて似た状態になることを自然に防ぐことができる。たまにそれがプラスにつながらないこともあるが、おおむねプラスに働く。順序が異なるが同じ・似た状態になることが多い場合は、それらを間引くような作業が必要になる。(でなくても間引く操作はたいてい行ったほうがよいが)
例:コマンドバトルRPGにおける「力をためる技と必殺技」など。こういう要素が多いほうがバラバラになりやすい。「7ダメージを与える技と20ダメージを与える技」のようなものは入れ替えてもあまり変わらないので対策が必要。
過去のAHCで確認
過去のAHCの問題について性質を見て解法を見直していく。
※途中で何をまとめているか自分でもわからなくなってしまったので書きかけで没になりました
どうしても見たい場合はこちら
自分が参加していたコンテスト
AHC014
既存の3点に1点を加えて長方形を作る問題。強い特徴として
・順序関係、それに対する強力な制約の存在
・順序入れ替えが可能でもスコア変化なし
・任意の途中段階に対して最終結果を見積もることは難しい
・ビームサーチで揃えたい「段階」の数値化が難しい
となり、否定的に山登り・焼きなましが良いと思われる。当時の自分は新参者で、貪欲+乱数で時間いっぱいやり直している(全破壊山登り)。
今なら部分破壊山登りかなあ。高速化しても焼ける段階までは見えてこないのだが当時の最上位陣はみんな焼いているらしい。改めてすごいな・・・。
部分破壊山登りは局所解にすぐはまりそうな構造ではあるので、焼いたほうがよくなるラインが比較的低いのかもしれない。
AHC016
今回の枠組みで考察するの難しそうな変わり種。グラフを過去に送る問題で、頂点番号情報がなくなることと、各辺一定確率で辺情報が反転するという問題。
・辺の有無が反転するときに乱数要素があるものの、正規分布を用いて発生数は見積もることができる。
・解自体は無茶苦茶少ない(元はどのグラフかを高々100通りから選ぶ)
という形なので、エラーが起こる前の候補について、何とかもっともらしさを見積もることができれば、そのもっともらしさが一番高いものを答える貪欲しかなさそう。煩雑な数式を正しく変形できる気力があるかが一つの壁になっていそう。
候補は自分で用意できるので、互いに大きく異なるグラフを選びたいが、当時の自分はクリークを思いつけなかった。
AHC018
硬さの異なるフィールドで、地面を掘って水道をつなげる問題。
問題のサイズがでかくてそのまま二次元配列を用意したくないし、近くのマスの硬さは近いという感じだったので、問題を小さい問題に圧縮。期待値的な最適行動はもう得られないだろうが、問題自体が難しいので許容していいと思う。
ランダム生成の硬さはそのマスを掘りきるまではっきりしないので、乱数要素は強め。これまでの結果に矛盾しないフィールドの生成が難しいため、モンテカルロ的なシミュレーションで解決はしなさそう。→ある種貪欲でいいんじゃないか?
AHC023
今やっても多分苦手な問題。不思議な形をした畑に作物を植える問題。作物も多いし問題の規模的に貪欲だったりDPだったりで決めるしかないんじゃないか?→いろいろそぎ落として本質だけになった最上位陣のものを見るとなんか焼けそうな情報量になってた。すごい。遷移も評価も想像以上に高速に動いてるみたいだし、データの持ち方やアルゴリズム次第で「うまくいきそう」の判定ラインが大きく変わるなあ。
AHC025
重さを知らないアイテムたちを天秤を使って何等分かにする。
乱数・インタラクティブの要素があるので全体を焼いたりビーム打ったりは無理である。これまでの結果に矛盾しない重さを確立を踏まえて生成するのが簡単ではないので、モンテカルロも難しい。これが簡単に生成できたらモンテカルロが最有力の可能性もあった。
各回ごとに天秤の使い方を決定するという問題として考えると、重さの予想がある程度つけば効率的な使い方を焼く・山登りするというのが有力か。
一番困るのが「効率的な使い方」の意味で、この問題はそれぞれの重さを特定していくのが良いとは限らなかったんだよなあ・・・。(特にクエリ数が足りない場合)
【PostMortem】HTTF2024 (AHC027)
※画像は公式Visualizerよりお借りしています
はじめに
この記事は2023/12/01 - 2023/12/10にAtCoderで行われましたAHC027の解法を紹介するものになります。いつもは冗長に書いているのですが、今回はいつもとちょっと違う切り口で、他の人の言及が少なそうなところを中心に書いてみます。(決して時間が取れなくて雑に書いているとかでは)
気を付けてはいるのですがところどころうっかり打ち間違っているかもしれません。間違いを発見されましたら優しく教えていただけるとありがたいです。
問題の概要
こちらは問題文を見ていただいたほうが早いと思われるので割愛します。簡単に言えば「部屋の汚れの平均が小さくなるように掃除ロボットを動かす」という問題です。
問題文はこちら
この問題では与えられた各マスの汚れやすさに比例して汚れの値がたまっていくので、汚れやすい所へは多めに掃除に回るのがよさそうという印象を受けます。
最終提出の解法
以下、最終提出の概要です。
言語:go言語
これはただの好みです。
解法:評価値をもとに1マスずつ動く貪欲
以下はTwitterで行った解法ツイートです。
暫定14位 最終提出の方針
— MON.T+α (@montplusa) 2023年12月10日
・「今の場所から最も評価値の高い場所をもとめ1マス進む」貪欲を可能な限り繰り返す
・最近通った場所についた場合は機械的にルートを反転させたり・・・
今回用いた評価値はほとんど同じ方針のものがAHC公式放送で述べられていた(公式放送にて√dにしたら44Mになったといわれているもの)ので、AHC公式放送の該当の解法をご存じない方はぜひご覧ください。(該当の解法以外にもいろいろ述べられていて参考になりました)一応、この先のセクションではそのあたり詳しいことは知らなくても、「最も評価の高いマスに1マス近づく」という貪欲を繰り返していることだけ知っていれば楽しめる内容になっています。
AHC公式放送(該当の解法の前準備は22:30くらいから)
公式解説では各マスの汚れを√dで計算する(本来の汚れを√dで割る)という方法が用いられていますが、実はこれは(現在のそのマスの訪問回数)で割ることで似たような結果が得られるので、こちらを採用しています。このほうが実際のマスの位置関係による行きやすさが若干反映されてよいような気がします。
貪欲の限界に挑戦
もう他の方の解法を確認している方はご存じの通り、このコンテストにおいて貪欲解法には大きな壁があります。というのも、貪欲解法はこの問題の持つ以下の特徴に対して弱いからです。
・道中うろうろしながらコンスタントに成果をあげることが大事
(評価値として、最短経路でないパスを用いた場合にあげられる成果を考慮しようとすると途端に難しくなる)
・かたまって汚れているエリアはとりきれないとすぐに戻ってくる羽目になる
(貪欲では汚れているエリアを分断するように突っ切ってしまうor途中で別の汚れているエリアの目標に方向転換してしまうことがあり、少ししてまた無駄に戻ることになる)
最終的に順位表の最上位あたりにいる方々のスコアは私の感覚では貪欲では達成できなさそうだな・・・という印象なのですが、貪欲でもここまではこれたよ、ということで一部をここに残しておこうと思います。誰か貪欲でさらに良い結果が出せている方がいれば教えてください。
貪欲における47.7Mの道のり
46~47Mあたりまでは改善の繰り返しで比較的順調だったのですが、そのあたりを超えてからはいろいろ苦しい中もがいていた記憶があります。もがいていた時に一番効果があった「反転テクニック」をここでは紹介します。
最近通った道についた場合に直近の経路を反転する
貪欲で移動経路を決めているときにいちばんよく起こるのが「ここさっき通ったばっかじゃん」パターンです。ということで、これを解消するために経路の反転を行います。
サンプルはseed=1での一場面です。
↑貪欲に評価の高いマスへと足を進めていたところ。botはこの後L(+そのあとにLD)とすすんで取りそびれた大きめの汚れを取りに行きます。

↑ところが、このターンの移動はついさっき汚れをとったばかりのところに行きついてしまい、無駄に一ターン消費してしまっています。

↑そこで、直近3回の移動を逆再生して、その動きを正式な動きとして改変してしまいます。移動の回数の合計を確認してみると、先ほど無駄に消費してしまった1ターンはなかったことになり、別の場所に移動することに成功しています。
↑結果、ここでは1マスの移動の追加だけで汚れの大きな場所の掃除をすることができました。
この後左上へULLと計画します。

↑ここで逆再生。(逆再生の長さは5)

↑今回は結局距離は縮まりませんでしたが、Lと進んでやり直すことができます。あるいは現在地が変わったので上のマスを取りに行くほうが評価が高くなっているかもしれません。
このテクニックは貪欲ベースで47M付近からスコアを改善するには必須のテクニックでした。
現在位置を分身させてしまう
上で述べた反転テクニックを使って大胆に現在位置を分身させてしまうのが有効です。
サンプルはまたしてもseed=1のこの場面です。
↑この場面は先ほどの反転テクニックを使って、移動回数を増やすことなく
↑この場面にできることを確認しました。また、最初の場面でU,Rを選択することで

↑このような場面にも到達できます。
さらに、最初の盤面→Lからの逆再生→Dからの逆再生を用いることで

↑こんな場面にも到達できたりします。(さらにこの場面からRからの逆再生で新しい場面に)
そんなわけで、これらの場面での現在位置の点を覚えておき、これらを距離0の点とします。これにたいして最短経路に対するDPを公式解説同様に行い、移動に都合の良い場面を持ってくることで改善が期待できます。
この分身戦法が使える場面は特定のケースでのみということはなく、取りこぼしを回収する際・別の汚れた区域へ移動する際に効果を発揮します。
例として、seed=1の別の場面を考えてみます。

↑この場面では、

↑この中から都合の良い視点を選ぶことができるということで、左・中央・右下の取りこぼしや左上の新しい区域への移動などいずれの方針に対しても大きなアドバンテージを得ることができます。
お掃除高橋君2号は現在位置を錯覚しているのでデバッグ出力をしてVisualizerを確認すると1マス進む貪欲での道の変わり方が面白いです。(以下はseed=1でのまた別の例)


意外にもDFSでのこれらの列挙はそれほど時間がかからず(ほぼ全列挙していますが、そもそも厳密に全列挙する必要はない)、手元の実験では最短経路についてのDP のほうが時間がかかるようでした。
これら(+諸々)を実装するとかなり貪欲らしからぬ振る舞いをしてくれるようになります。貪欲を頑張ってみたら最終的に行き着くのは貪欲らしからぬ動きという、現実を突きつけられる結果になりました・・・。
seed=5 (注:実際の行動は長さが70000くらいあるので一部分のみを抜粋しています)
改善の余地
容易に想像できることですが、この貪欲のポテンシャルはそれほど高くないです。特に区域を訪れる頻度の認識が最短路に限定したDPでは甘く、この頻度については反転では対応できません。
また、反転によって本来訪れる予定だったターンから多少前後していることで若干コストが増えてしまいます。かといって、スコア計算の処理を導入すると出力できる行動の長さが短くなってしまいループのつなぎ目での無駄が無視できなくなってしまいます。(私の解法では各マスの評価の値に(現在の汚れ)/(訪問回数)を入れていることもあって長さが長いほうが強いです。)
評価値を謎の(軽い定数時間程度で計算できる)見積もり項で修正するorDP部分自体を工夫するなどして上の問題が解消できるなら、まだまだ改善が可能だと思います(いろいろ突き詰めて多分~2%くらいで、それ以上を目指すならさすがにビームを打つか、さっさと経路を完成させて後からいろいろ変形させないと厳しそう)
そんなわけで、この貪欲はある程度頭打ちになっており、wataさんの順位表を確認してみると安定して最上位陣に敗北しています。(これらの統計データを公開してくださっている方々、いつもありがとうございます)
おわりに
ここまで読んでくださった方、ありがとうございました。今回は高速に焼くのが難しそうで貪欲ベースで頑張ってみましたが、なかなか戦えたのではないかと思っています。一方で最終的に高速な焼きなましにもっていく人たちには歯が立たず、実力不足を感じています。ビームサーチもそろそろまともに向き合っていかないと・・・。
今回のコンテストのテーマは一度過去に作ってみたいと思っていたいたので、コンテストという形できれいなビジュアライザとともに楽しめたのが嬉しかったです。コンテストの開催に関わってくださっていた方々、他参加されていた方々、楽しい時間をありがとうございました!
おまけ
以下はコンテスト中・後に思ったことを雑多に書いたものです。
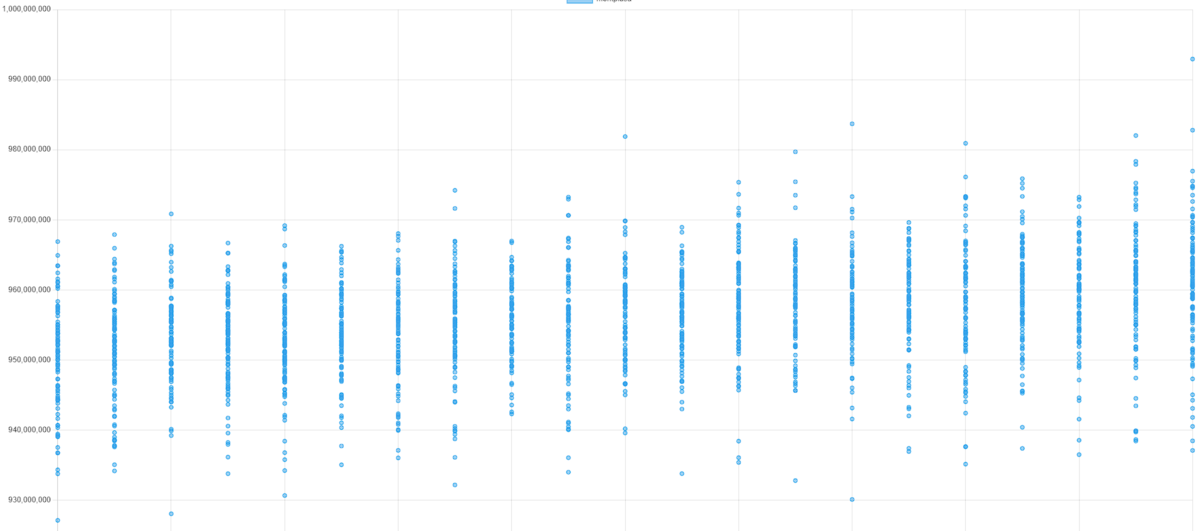
・wataさんの順位表を見ていると15位のtokoharuさんも全ケースのスコア安定してらっしゃるなーと思ってみていたら、チーム戦を疑われるくらい相関が高くて笑ってしまった。
tokoharuさん(15位)との比較

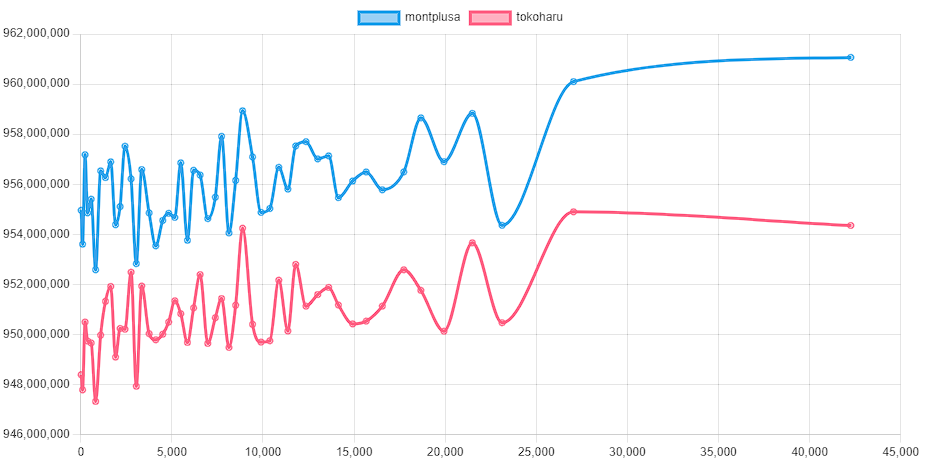
(参考:kawateaさん(13位)との比較。ふつうはこれくらい相関が薄いので、tokoharuさんとは方針が近いのかも?)

・今回の問題設定では汚れやすさという値としてdが与えられていたが、汚れやすさにオフィス内の重要度を掛け算してやると(隅っこやあまり利用されてない部屋は低めの値を設定し社長室や応接室を高めに設定するなど)、より満足度の高いロボットになりそう。
【Postmortem】AHC025

※画像は公式Visualizerよりお借りしています
はじめに
この記事は2023/10/14 - 2023/10/22にAtCoderで行われましたAHC025の解法を紹介するものになります。
初めまして(orお久しぶりです)。参加記を書こうとはてなブログを開くと最後に参加記を公開してからもう半年以上であることに気づきました・・・。この間いくつかAtCoder・CodinGameのコンテストには出ていたのですが、コンテスト期間に大きな用事が入っていたり、短期コンは思ったものを実装してなかったり、はたまたコンテスト終了後参加記を書こうとしているところに用事立て込んでしまったりで書けていなかったんですね。今回のAHCは久しぶりにこれといった大きな用事に被ることもなくがっつり参加することができたため、一度考えたことなどをまとめておこうかと思います。
このPostmortemは自分自身のコンテスト中の思考を改めて整理するために書いているものでもあるため、解法とともにそこに至った考えなど少々冗長に書いております。見てくださっている方はもし長いと感じたら是非見出しだけを流し読みするだけでも概略がわかるのでぜひ見てみてください。
一週間いろいろ試行錯誤し、最終的に3位(&初赤perf)という結果になりました!
気を付けてはいるのですがところどころうっかり打ち間違っているかもしれません。間違いを発見されましたら優しく教えていただけるとありがたいです。
問題の概要
こちらは問題文を見ていただいたほうが早いと思われるので割愛します。簡単に言えば「天秤を使って重さのわからないアイテムを袋に均等に分ける」という問題です。
問題文はこちら
この問題では
・アイテムの数
・袋の数
・天秤を使ってよい回数
がケースにより異なり、特に三つ目の要素は大小によって問題の雰囲気が大きく変わるので、このケースによる違いを何とかするのが難しいところでした。
最終提出の解法
以下、最終提出の概要です。
言語:go言語
これはただの好みです。
解法:一番重い袋と一番軽い袋を均すことを繰り返す山登り
以下はTwitterで行った解法ツイートです。
AHC025 暫定3位 方針
— MON.T+α (@montplusa) 2023年10月22日
・一番重い袋から一番軽い袋に一つ移動させてみる
・(上が厳しくなってきたら)一番重い袋と一番軽い袋でいくつか入れ替えて均せるか試す
クエリ数が十分大きいときは上を試す前にアイテムの重い順を確認することで精度を上げていました
もう少し詳細を確認していきます。
まず、遷移云々の前に根本的な部分を確認します。
今回の問題は最終的にアイテムをまんべんなく分けられた解を出力するわけですが、Validな解に対して、実際にどのくらいばらつきなく分けられているかを天秤で判定するのはかなり難しいです(天秤はどのくらい差があるかを返さないため)。よって、
・何らかの初期解を与えて明らかに改善するほうへ遷移できないか試す
という方針を基本方針としました。これにより「実際にはどのくらいまんべんなくできているのか分からないけれども多分良い感じの解」に到達します。初期解として、今回はアイテムiを袋i%Dに入れるものとしました。
次に、遷移1→遷移2と二種類用意していますが、実装した時系列的にも、本質的にも、基本となるのは二つ目の遷移ですので、二つ目の遷移から先に紹介します。
遷移2 二つの袋を足して2で割る
いったんアイテムを水とします。そうすると「二つのコップの水を足して2で割る」という操作、何度も繰り返すとかなり速いスピードで均等になる気がしませんか?(多分指数的に収束させられそう)
ということでこの遷移を採用しました。また、この遷移を行うために、必然的に「重さ(あるいは全体に占める各荷物の割合)」を見つもる必要がありました。この見つもるステップについてはもう少し後で紹介します。
この操作は、一番重い袋と一番軽い袋で行うと効果があります。ほかでも効果はありますが、他の袋を選んでしまうと二つとも平均より重い袋だったりして効率的でない可能性があります。かといって一番重い袋のアイテムがあまり融通が利かないタイプだったりして早々に局所解にはまってしまうなど、難しいと感じる場面では他の袋を選んだりします。
袋の重さ順はおそらく挿入ソートといわれるもので決定しました。
(重さ順の決定は初回はDlogD回くらいのクエリでできる。重い袋と軽い袋の中身を更新したときは重さ順の再決定に2*logD回くらいのクエリを要する)
よくよく考えるとこのソート方法の部分はいろいろクエリを節約する方法を考えてみてもよかったかもしれません。
この足して2で割る操作は重さの推定値で行うので、実際には元の時よりならせているかを確認しなければなりません。この部分はほかの方でもよく見たので結論だけ書きますが、袋1を一番重い袋、袋2を一番軽い袋としたときに
(袋1→袋1となる予定のアイテム)>(袋2→袋2となる予定のアイテム)
(袋1→袋2となる予定のアイテム)>(袋2→袋1となる予定のアイテム)
が重さについて成り立っていればよいです。
遷移2は重さの真値がわかっている場合にはすぐにいい解へたどり着けるのですが、今回のような真値がわかっていない場合にはある程度重さの推定値に確信がないと効果が安定せず、博打になります。特にクエリ数が少ない場合では運の良し悪しでスコアが乱高下してしまうので、これを他提出者のスコアと競わせると一部のケースで大幅に順位を落としてしまいます。
遷移1 一番重い袋から一番軽い袋へ一つ移動する
遷移2の不安定さを解消するために生まれたのが、この遷移1になります。遷移2が博打タイプとすると、遷移1は着実タイプになります。というのも、この遷移では遷移に成功すると以下の二つのパターンが考えられますが、いずれもある程度大きいメリットがあるからです。
パターン1 遷移したが一番重い袋と一番軽い袋の重さが逆転しない場合
この場合はアイテム一個移動させた分二つの袋を順調に縮められているので嬉しいです。遷移2では軽い袋から重い袋に行った分も合わせると実際にはほとんど改善していない可能性もあるので・・・
パターン2 遷移した結果一番重い袋と一番軽い袋の重さが逆転した場合
この場合はどれだけよくなったかはよくわからないですが、この結果から「もうすべての袋にある程度均等に入っている」あるいは「移動させたアイテムがそれなりに重い」のどちらかであることがわかり、大事な情報が得られる点で嬉しいです。
遷移1ではこのほか遷移に失敗したときにもパターン2のような情報を得られるので、クエリに対してどのような結果が来てもある程度の成果が得られる点で安心です。
遷移で改善するかの判定は遷移2と同じ方法を採用します。(この場合2つ目の不等式は明らかです)
補正1 これまでのクエリで得た不等式をすべて記録しておき、新しいクエリを実行するごとに重さを更新
おそらく一番重要な補正部分の話になります。クエリは実行したら履歴として記憶しておき、クエリを実行するごとに、以下の修正をこれまでの各クエリに対して行います
(1)現在の重さの予想値について、クエリの結果と合致しているか見る
(2)合致していなかったら、少し過剰に修正する("<"であれば、例えば45:55くらいになるように対象グループの重さを線形に縮める・伸ばす)
(2)での「過剰」の具合が大きいと重さの予測値は大きく変わり、この具合が小さいと、重さの予測値の変更はある程度穏やかになります。(もちろん、もとが70:30のような予想になっていたときは49.9:50.1のような値に変更する場合でも大きく変わります)
ここで、基本的に自分がクエリが投げるタイミングは
・遷移2の二分割の改善判定
・遷移後の袋の重さ順の更新
の二つなので、改善がうまくいっていくことを考えると必然的にクエリはどんどん真値が50:50に近いものを判定していくことがわかります。そのため、「過剰」の具合はクエリが進むごとに穏やかにしていくのが自然な流れになります。
この穏やかにするはやさですが、
穏やかにするのが早め→多くのケースでいい感じなものの一部の運が悪いケースで修正力が足りない
穏やかにするのが遅め→大きく失敗するケースはなくなるものの、どれだけうまくいっても「過剰」の具合の分だけ重さの推定値がぶれ続けるため、とても良い解(最適解や提出者内1位とかの解)への到達率は低くなる
という難しい問題があり、最終的に安定をとって後者を選択しました。結果的にこれが正解だったのかはわかりません。
補正2 これまでに袋にどんなアイテムが入っていて重さがどの順だったかを記録しておき、遷移を試すたびに重さを更新
補正1の補正方法はあくまで各クエリに対して順番に処理していくだけなので、この操作の後にすべてのクエリの結果に反しない推定値になっているかというとそうではなく、また、このことに加えて、クエリには袋の重さ比較に関しては二分探索で必要だった部分しか入っていないため、袋の重さ順の情報が生かし切れていない雰囲気でした。そこで考えたのがこの補正2です。
これは(金曜か土くらいの)1ページ目に入ってから入れた補正で、この補正は実装当時あまりうまくいく気がしなかったですが、着実に効いていました。
補正2は、遷移を試すたびにいくつかのクエリによって推定値が変わるので、これが過去のアイテムの割り当てに対して、重さ順が正しくなっているかを確認します。
補正方法が面白いので図で紹介します。(効果の裏付けのないこの補正はだれもやらんやろと思ったら既にeijirouさんが同じような方法を紹介されていました・・・)
1.過去の割り当てに対して、現在の推定値で各袋の重さはどうなっているか調べる

過去のアイテム割り当てについて、現在の推定値では各袋の重さが上の図のように予想されたとします。ここで、実際には袋は左が一番重く、右が一番軽いことが分かっているとします。
2.重さの合計値をソート
各アイテムの情報を消して袋の重さの推定値をソートします。
ソート前
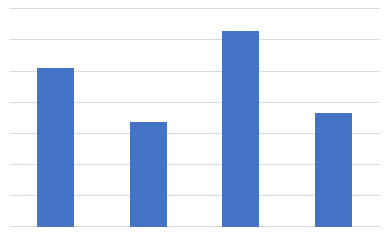
ソート後
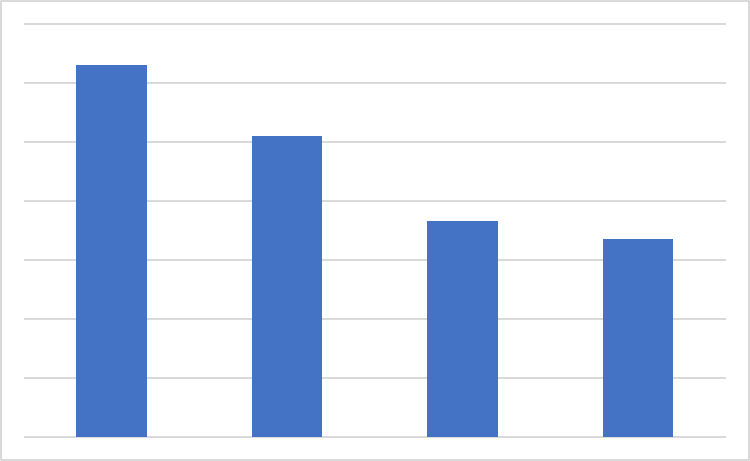
3.シルエットに合うようにアイテムの重さを縮める・伸ばす

補正3 クエリ数が十分あるなら、最初に各アイテムの重い順を調べて、遷移を試すたびに重さを更新
クエリ数が十分にあるなら、各アイテムの重い順は確認したほうが圧倒的にパフォーマンスがよくなります。というのも、最初に重い順を調べておいた場合、山登りフェーズを以下の推定値(多分期待値)から始めることで非常にいいスタートを切ることができるからです。また、補正1・補正2の推定値の変更が適切な方向でなかったときや大きく変更を加えてしまったときは推定値がアイテムの重さ順に反していることが多く、重さ順を知っておくことで的外れな方向に進まなくなり、クエリ数が多くなるほど効果が顕著になります。
アイテムがN個の場合
(1番軽いアイテムの重さ)=100000/N
(2番目に軽いアイテムの重さ)=100000/N+100000/(N-1)
(1番重いアイテムの重さ)=100000/N+100000/(N-1)+・・・+100000/1
このアイテムの重さ順による補正は、それぞれをアイテム1つのグループとみなし、補正2の方法を使って遷移を試すたびに行います。
山登りフェーズを始める前にそれらしい初期状態・初期推定値を考える
山登りフェーズに入る前に、ある程度いい状態から始められるならそれに越したことはないので考えてみることにしました。クエリ数が大きいときにはあまり大した問題にはならないですが、クエリ数が小さい場合だと基本的に山は登り切れないのでそれなりに効果があります。
まず、全アイテムを二つのグループ(今の推定値で半々と思われる分け方)にします。これに対し、クエリを消費して結果を確認します。
この操作はクエリを使える回数に応じて5回~20回おこなわれ、そのたびに補正1が働きます。
重さの順番がわかっている場合は、補正3で述べた推定値と今の補正1がかなり筋の良い推定をしているので、全アイテムをD個のグループ(今の推定値でそれぞれ1/Dと思われる分け方)にし、これを初期解にします。これくらい正確です。
重さの順がわかっていない場合は、5~20回のクエリでは必ずしも適切な方向に推定が行われておらず、重さ1万以下のアイテムが10万以上で見積もられていたりもします。上と同じように推定値で初期状態を設定しても良いんですが、その初期状態が良いかどうかは博打になります。今回の順位準拠スコアにおいて絶対に避けたいのが「i番目のアイテムをi%D番目に入れるのを初期状態としてシンプルな遷移を繰り返す」というタイプの手法に負けることで、このタイプに負けないためにi番目のアイテムをi%D番目に入れるのを初期状態とします。こうすることで、この初期状態がうまく遷移しやすい場合に大勢に抜かされる可能性を下げています。(なお本当にうまくいっているかは・・・?)
加えて、重さの順がわかっていない場合は、この初期状態に対して袋の重さ順を確認すると、何となく各袋の重さがわかってきます(直感的にも、特にDが大きい場合には、一番軽かった袋は何となく平均よりかなり軽いことが予想できます)。これは具体的には指数分布の乱数を繰り返し生成することで期待値を求めて、アイテムの重さを縮める・伸ばすという操作を行います。
明らかに結果のわかっているクエリは省略する
いくつか、クエリを消費しなくても明らかにわかる結果があります。おおよそ以下の通りです。
・天秤の一方あるいは両方が空の場合(これは逆にクエリを投げるとWAになってしまいます)
・過去のクエリと同一の場合
・アイテムの重さ順がわかっていて、片方がもう一方の上位互換の場合(つまりもう一方の各アイテムに対して、一方に対応するそれより大きいアイテムがある場合)
これらの場合はクエリを消費せずにその結果を利用します。
おわりに
ここまで読んでくださった方、ありがとうございました。久しぶりにがっつり取り組めたのもありますが、ratedのAHCでここまでのパフォーマンスが出たのは初めてだったので自分でもびっくりしています。CodinGameといい、もしかして対人要素が得意なのでは・・・?
今回は天秤と分割というシンプルな問題でしたが、入力の値によって各方針の得意不得意が分かれる面白い問題でした。次回の長期AHCはまだ明らかになっていなかったと思いますが、次回のテーマが今から楽しみです。改めて、コンテストの開催に関わってくださっていた方々、他参加されていた方々、楽しい時間をありがとうございました!
おまけ
以下は解法の補足情報を雑多に書いたものです。
・実はクエリ数が多いときは局所解にはまることがちょくちょくあり、ひどい局所解で止まらないように根性で三つの袋を再編成する遷移が存在する(が、たぶん10ケースに1回ぐらいしかこの遷移見かけない)
・アイテムの重さ順を判定するかどうかは具体的にはクエリ数が
アイテムの重さ順を調べるのにかかる回数(NlogN)+初期解の袋の重さ順を調べるのにかかる回数(DlogD)+30(初期状態から何回か遷移を行うのにかかるとおもわれる回数)
を超えているかで決めていた。何回か遷移を行えないくらいぎりぎりだと、雑な初期解から遷移を繰り返したほうがパフォーマンスが高かった。
・指定したアイテム群を指定した数に分割する関数(中の実装は超高温の焼きなまし)を用意することで、全アイテム半分に分けるときや、D分割するとき、最大の袋と最小の袋を足して割るとき、三つの袋を再編成する遷移など、いろんなときに使える(ここは既存のアルゴリズムを採用してもよかったものの、厳密解でなくても、近似比が保証されてなくてもよかったのでまあいいか・・・)
・クエリを投げようとしている比較に対して、「今の推定値の予想に反する結果を仮定して補正をかけてみても過去のクエリ・重さ順の補正によって今の予想に戻ってくるか」という関数があり、何回も反する結果を仮定しなおして試すことで遷移2のクエリは安心な方を後回しにしてクエリを投げている
・補正2と補正3は実は同じ枠組みで管理している
・今回とくに高速化は求められなかったので、各袋のアイテムをslice(可変長配列)で管理するなど、ほとんどは愚直なデータ構造を用いている
・実は重さ順がわかっているときの推定値は若干補正しているが、ほぼ推定値の結果が誤差なので省略した
以下はコンテスト中・後に思ったことを雑多に書いたものです。
・使っていないものの、ソート済みのアイテムの重さの生成は、遷移3で述べた初期推定値の式を参考にすると多分O(NlogN)ではなくO(N)でできる
・各ケースでの順位によるスコア計算、良いアルゴリズムがかなり母集団によらないか・・・?(基本的には多くの人が到達する解に+αした点に到達できるプログラムがある程度強く、今回だと、第一の波として順番にアイテムを配置した初期解、第二の波として初期解から最大の袋から最小の袋へ移動させる遷移の局所解がありそう。クエリ数が多い場合で最適解を求めてくるみたいな異常集団の波もあるかと思ったがさすがにそんなことはなかった)
・遷移2を実装して「これからクエリ数の大きいケースについて最適解に近づけていくぞ」という気持ちになっていたところ、たまたま起きてしまったREによりクエリ数の大きいケースの失点は大した問題になっていないことが分かってしまった(重さ順を確認するケースは暫定テストで58ケースあり、ここでの失点は0.3Mだったので、当時のスコアから他42ケースで3M近く落としていたことが分かった)ので、最適解方向の話は打ち切ってクエリ数が小さい時の安定化を考えることになった。
・今回の点数は100Mから各ケースで順位を落とした分だけ下がるので、遷移2により90Mくらいまでは上がりやすかったものの97M→98Mへの改善が思ってた以上にかなり遠かった・・・(この試行錯誤の間に他の人も良くなったプログラムを提出して少しずつ各ケースでの争いが激しくなっていたのもあるかもしれない)
・「アイテムの重さ、一番当たりそうな数字を言ってください」といわれると1なのだが、もちろんこんな推定がいいわけがなく・・・。
・マージソートやLargest Differencing Methodなどがコンテスト後に話題になっていた。確認してみるとどちらも今のプログラムに取り入れられる部分があるなあとなり反省。
・いろいろな方の解法ツイートや記事を見る感じ、割と基本的な方針はみんな同じなのかな?遷移をどうするかと推定方法(あるいは推定しない)が何パターンかありそう。
・simanさんが作ってくださった統計を見るに、無事安定志向のプログラムになっていそう。途中でクエリが小さいほうの対策をしていなかったら悲惨なことになってただろうな・・・。統計によってNに対してそれぞれどのような方針が有効なのかが何となく透けて見えるのも面白い。