
※画像は公式Visualizerよりお借りしています
はじめに
この記事は2023/10/14 - 2023/10/22にAtCoderで行われましたAHC025の解法を紹介するものになります。
初めまして(orお久しぶりです)。参加記を書こうとはてなブログを開くと最後に参加記を公開してからもう半年以上であることに気づきました・・・。この間いくつかAtCoder・CodinGameのコンテストには出ていたのですが、コンテスト期間に大きな用事が入っていたり、短期コンは思ったものを実装してなかったり、はたまたコンテスト終了後参加記を書こうとしているところに用事立て込んでしまったりで書けていなかったんですね。今回のAHCは久しぶりにこれといった大きな用事に被ることもなくがっつり参加することができたため、一度考えたことなどをまとめておこうかと思います。
このPostmortemは自分自身のコンテスト中の思考を改めて整理するために書いているものでもあるため、解法とともにそこに至った考えなど少々冗長に書いております。見てくださっている方はもし長いと感じたら是非見出しだけを流し読みするだけでも概略がわかるのでぜひ見てみてください。
一週間いろいろ試行錯誤し、最終的に3位(&初赤perf)という結果になりました!
気を付けてはいるのですがところどころうっかり打ち間違っているかもしれません。間違いを発見されましたら優しく教えていただけるとありがたいです。
問題の概要
こちらは問題文を見ていただいたほうが早いと思われるので割愛します。簡単に言えば「天秤を使って重さのわからないアイテムを袋に均等に分ける」という問題です。
問題文はこちら
この問題では
・アイテムの数
・袋の数
・天秤を使ってよい回数
がケースにより異なり、特に三つ目の要素は大小によって問題の雰囲気が大きく変わるので、このケースによる違いを何とかするのが難しいところでした。
最終提出の解法
以下、最終提出の概要です。
言語:go言語
これはただの好みです。
解法:一番重い袋と一番軽い袋を均すことを繰り返す山登り
以下はTwitterで行った解法ツイートです。
AHC025 暫定3位 方針
— MON.T+α (@montplusa) 2023年10月22日
・一番重い袋から一番軽い袋に一つ移動させてみる
・(上が厳しくなってきたら)一番重い袋と一番軽い袋でいくつか入れ替えて均せるか試す
クエリ数が十分大きいときは上を試す前にアイテムの重い順を確認することで精度を上げていました
もう少し詳細を確認していきます。
まず、遷移云々の前に根本的な部分を確認します。
今回の問題は最終的にアイテムをまんべんなく分けられた解を出力するわけですが、Validな解に対して、実際にどのくらいばらつきなく分けられているかを天秤で判定するのはかなり難しいです(天秤はどのくらい差があるかを返さないため)。よって、
・何らかの初期解を与えて明らかに改善するほうへ遷移できないか試す
という方針を基本方針としました。これにより「実際にはどのくらいまんべんなくできているのか分からないけれども多分良い感じの解」に到達します。初期解として、今回はアイテムiを袋i%Dに入れるものとしました。
次に、遷移1→遷移2と二種類用意していますが、実装した時系列的にも、本質的にも、基本となるのは二つ目の遷移ですので、二つ目の遷移から先に紹介します。
遷移2 二つの袋を足して2で割る
いったんアイテムを水とします。そうすると「二つのコップの水を足して2で割る」という操作、何度も繰り返すとかなり速いスピードで均等になる気がしませんか?(多分指数的に収束させられそう)
ということでこの遷移を採用しました。また、この遷移を行うために、必然的に「重さ(あるいは全体に占める各荷物の割合)」を見つもる必要がありました。この見つもるステップについてはもう少し後で紹介します。
この操作は、一番重い袋と一番軽い袋で行うと効果があります。ほかでも効果はありますが、他の袋を選んでしまうと二つとも平均より重い袋だったりして効率的でない可能性があります。かといって一番重い袋のアイテムがあまり融通が利かないタイプだったりして早々に局所解にはまってしまうなど、難しいと感じる場面では他の袋を選んだりします。
袋の重さ順はおそらく挿入ソートといわれるもので決定しました。
(重さ順の決定は初回はDlogD回くらいのクエリでできる。重い袋と軽い袋の中身を更新したときは重さ順の再決定に2*logD回くらいのクエリを要する)
よくよく考えるとこのソート方法の部分はいろいろクエリを節約する方法を考えてみてもよかったかもしれません。
この足して2で割る操作は重さの推定値で行うので、実際には元の時よりならせているかを確認しなければなりません。この部分はほかの方でもよく見たので結論だけ書きますが、袋1を一番重い袋、袋2を一番軽い袋としたときに
(袋1→袋1となる予定のアイテム)>(袋2→袋2となる予定のアイテム)
(袋1→袋2となる予定のアイテム)>(袋2→袋1となる予定のアイテム)
が重さについて成り立っていればよいです。
遷移2は重さの真値がわかっている場合にはすぐにいい解へたどり着けるのですが、今回のような真値がわかっていない場合にはある程度重さの推定値に確信がないと効果が安定せず、博打になります。特にクエリ数が少ない場合では運の良し悪しでスコアが乱高下してしまうので、これを他提出者のスコアと競わせると一部のケースで大幅に順位を落としてしまいます。
遷移1 一番重い袋から一番軽い袋へ一つ移動する
遷移2の不安定さを解消するために生まれたのが、この遷移1になります。遷移2が博打タイプとすると、遷移1は着実タイプになります。というのも、この遷移では遷移に成功すると以下の二つのパターンが考えられますが、いずれもある程度大きいメリットがあるからです。
パターン1 遷移したが一番重い袋と一番軽い袋の重さが逆転しない場合
この場合はアイテム一個移動させた分二つの袋を順調に縮められているので嬉しいです。遷移2では軽い袋から重い袋に行った分も合わせると実際にはほとんど改善していない可能性もあるので・・・
パターン2 遷移した結果一番重い袋と一番軽い袋の重さが逆転した場合
この場合はどれだけよくなったかはよくわからないですが、この結果から「もうすべての袋にある程度均等に入っている」あるいは「移動させたアイテムがそれなりに重い」のどちらかであることがわかり、大事な情報が得られる点で嬉しいです。
遷移1ではこのほか遷移に失敗したときにもパターン2のような情報を得られるので、クエリに対してどのような結果が来てもある程度の成果が得られる点で安心です。
遷移で改善するかの判定は遷移2と同じ方法を採用します。(この場合2つ目の不等式は明らかです)
補正1 これまでのクエリで得た不等式をすべて記録しておき、新しいクエリを実行するごとに重さを更新
おそらく一番重要な補正部分の話になります。クエリは実行したら履歴として記憶しておき、クエリを実行するごとに、以下の修正をこれまでの各クエリに対して行います
(1)現在の重さの予想値について、クエリの結果と合致しているか見る
(2)合致していなかったら、少し過剰に修正する("<"であれば、例えば45:55くらいになるように対象グループの重さを線形に縮める・伸ばす)
(2)での「過剰」の具合が大きいと重さの予測値は大きく変わり、この具合が小さいと、重さの予測値の変更はある程度穏やかになります。(もちろん、もとが70:30のような予想になっていたときは49.9:50.1のような値に変更する場合でも大きく変わります)
ここで、基本的に自分がクエリが投げるタイミングは
・遷移2の二分割の改善判定
・遷移後の袋の重さ順の更新
の二つなので、改善がうまくいっていくことを考えると必然的にクエリはどんどん真値が50:50に近いものを判定していくことがわかります。そのため、「過剰」の具合はクエリが進むごとに穏やかにしていくのが自然な流れになります。
この穏やかにするはやさですが、
穏やかにするのが早め→多くのケースでいい感じなものの一部の運が悪いケースで修正力が足りない
穏やかにするのが遅め→大きく失敗するケースはなくなるものの、どれだけうまくいっても「過剰」の具合の分だけ重さの推定値がぶれ続けるため、とても良い解(最適解や提出者内1位とかの解)への到達率は低くなる
という難しい問題があり、最終的に安定をとって後者を選択しました。結果的にこれが正解だったのかはわかりません。
補正2 これまでに袋にどんなアイテムが入っていて重さがどの順だったかを記録しておき、遷移を試すたびに重さを更新
補正1の補正方法はあくまで各クエリに対して順番に処理していくだけなので、この操作の後にすべてのクエリの結果に反しない推定値になっているかというとそうではなく、また、このことに加えて、クエリには袋の重さ比較に関しては二分探索で必要だった部分しか入っていないため、袋の重さ順の情報が生かし切れていない雰囲気でした。そこで考えたのがこの補正2です。
これは(金曜か土くらいの)1ページ目に入ってから入れた補正で、この補正は実装当時あまりうまくいく気がしなかったですが、着実に効いていました。
補正2は、遷移を試すたびにいくつかのクエリによって推定値が変わるので、これが過去のアイテムの割り当てに対して、重さ順が正しくなっているかを確認します。
補正方法が面白いので図で紹介します。(効果の裏付けのないこの補正はだれもやらんやろと思ったら既にeijirouさんが同じような方法を紹介されていました・・・)
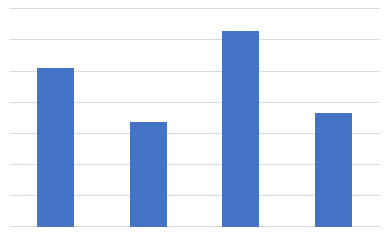
1.過去の割り当てに対して、現在の推定値で各袋の重さはどうなっているか調べる

過去のアイテム割り当てについて、現在の推定値では各袋の重さが上の図のように予想されたとします。ここで、実際には袋は左が一番重く、右が一番軽いことが分かっているとします。
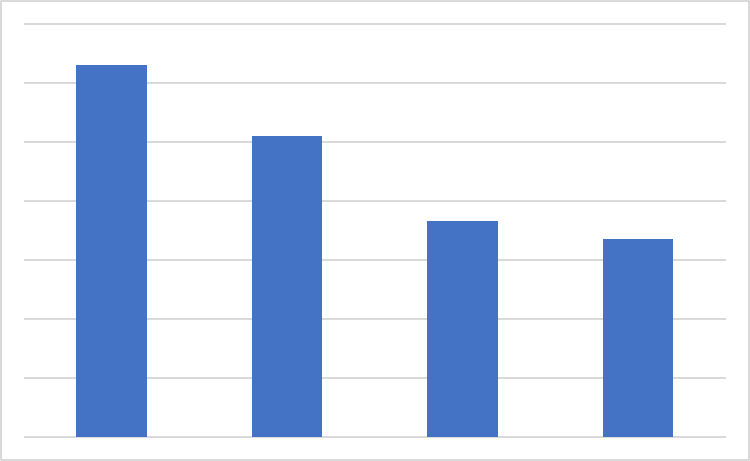
2.重さの合計値をソート
各アイテムの情報を消して袋の重さの推定値をソートします。
ソート前
ソート後
3.シルエットに合うようにアイテムの重さを縮める・伸ばす

補正3 クエリ数が十分あるなら、最初に各アイテムの重い順を調べて、遷移を試すたびに重さを更新
クエリ数が十分にあるなら、各アイテムの重い順は確認したほうが圧倒的にパフォーマンスがよくなります。というのも、最初に重い順を調べておいた場合、山登りフェーズを以下の推定値(多分期待値)から始めることで非常にいいスタートを切ることができるからです。また、補正1・補正2の推定値の変更が適切な方向でなかったときや大きく変更を加えてしまったときは推定値がアイテムの重さ順に反していることが多く、重さ順を知っておくことで的外れな方向に進まなくなり、クエリ数が多くなるほど効果が顕著になります。
アイテムがN個の場合
(1番軽いアイテムの重さ)=100000/N
(2番目に軽いアイテムの重さ)=100000/N+100000/(N-1)
(1番重いアイテムの重さ)=100000/N+100000/(N-1)+・・・+100000/1
このアイテムの重さ順による補正は、それぞれをアイテム1つのグループとみなし、補正2の方法を使って遷移を試すたびに行います。
山登りフェーズを始める前にそれらしい初期状態・初期推定値を考える
山登りフェーズに入る前に、ある程度いい状態から始められるならそれに越したことはないので考えてみることにしました。クエリ数が大きいときにはあまり大した問題にはならないですが、クエリ数が小さい場合だと基本的に山は登り切れないのでそれなりに効果があります。
まず、全アイテムを二つのグループ(今の推定値で半々と思われる分け方)にします。これに対し、クエリを消費して結果を確認します。
この操作はクエリを使える回数に応じて5回~20回おこなわれ、そのたびに補正1が働きます。
重さの順番がわかっている場合は、補正3で述べた推定値と今の補正1がかなり筋の良い推定をしているので、全アイテムをD個のグループ(今の推定値でそれぞれ1/Dと思われる分け方)にし、これを初期解にします。これくらい正確です。
重さの順がわかっていない場合は、5~20回のクエリでは必ずしも適切な方向に推定が行われておらず、重さ1万以下のアイテムが10万以上で見積もられていたりもします。上と同じように推定値で初期状態を設定しても良いんですが、その初期状態が良いかどうかは博打になります。今回の順位準拠スコアにおいて絶対に避けたいのが「i番目のアイテムをi%D番目に入れるのを初期状態としてシンプルな遷移を繰り返す」というタイプの手法に負けることで、このタイプに負けないためにi番目のアイテムをi%D番目に入れるのを初期状態とします。こうすることで、この初期状態がうまく遷移しやすい場合に大勢に抜かされる可能性を下げています。(なお本当にうまくいっているかは・・・?)
加えて、重さの順がわかっていない場合は、この初期状態に対して袋の重さ順を確認すると、何となく各袋の重さがわかってきます(直感的にも、特にDが大きい場合には、一番軽かった袋は何となく平均よりかなり軽いことが予想できます)。これは具体的には指数分布の乱数を繰り返し生成することで期待値を求めて、アイテムの重さを縮める・伸ばすという操作を行います。
明らかに結果のわかっているクエリは省略する
いくつか、クエリを消費しなくても明らかにわかる結果があります。おおよそ以下の通りです。
・天秤の一方あるいは両方が空の場合(これは逆にクエリを投げるとWAになってしまいます)
・過去のクエリと同一の場合
・アイテムの重さ順がわかっていて、片方がもう一方の上位互換の場合(つまりもう一方の各アイテムに対して、一方に対応するそれより大きいアイテムがある場合)
これらの場合はクエリを消費せずにその結果を利用します。
おわりに
ここまで読んでくださった方、ありがとうございました。久しぶりにがっつり取り組めたのもありますが、ratedのAHCでここまでのパフォーマンスが出たのは初めてだったので自分でもびっくりしています。CodinGameといい、もしかして対人要素が得意なのでは・・・?
今回は天秤と分割というシンプルな問題でしたが、入力の値によって各方針の得意不得意が分かれる面白い問題でした。次回の長期AHCはまだ明らかになっていなかったと思いますが、次回のテーマが今から楽しみです。改めて、コンテストの開催に関わってくださっていた方々、他参加されていた方々、楽しい時間をありがとうございました!
おまけ
以下は解法の補足情報を雑多に書いたものです。
・実はクエリ数が多いときは局所解にはまることがちょくちょくあり、ひどい局所解で止まらないように根性で三つの袋を再編成する遷移が存在する(が、たぶん10ケースに1回ぐらいしかこの遷移見かけない)
・アイテムの重さ順を判定するかどうかは具体的にはクエリ数が
アイテムの重さ順を調べるのにかかる回数(NlogN)+初期解の袋の重さ順を調べるのにかかる回数(DlogD)+30(初期状態から何回か遷移を行うのにかかるとおもわれる回数)
を超えているかで決めていた。何回か遷移を行えないくらいぎりぎりだと、雑な初期解から遷移を繰り返したほうがパフォーマンスが高かった。
・指定したアイテム群を指定した数に分割する関数(中の実装は超高温の焼きなまし)を用意することで、全アイテム半分に分けるときや、D分割するとき、最大の袋と最小の袋を足して割るとき、三つの袋を再編成する遷移など、いろんなときに使える(ここは既存のアルゴリズムを採用してもよかったものの、厳密解でなくても、近似比が保証されてなくてもよかったのでまあいいか・・・)
・クエリを投げようとしている比較に対して、「今の推定値の予想に反する結果を仮定して補正をかけてみても過去のクエリ・重さ順の補正によって今の予想に戻ってくるか」という関数があり、何回も反する結果を仮定しなおして試すことで遷移2のクエリは安心な方を後回しにしてクエリを投げている
・補正2と補正3は実は同じ枠組みで管理している
・今回とくに高速化は求められなかったので、各袋のアイテムをslice(可変長配列)で管理するなど、ほとんどは愚直なデータ構造を用いている
・実は重さ順がわかっているときの推定値は若干補正しているが、ほぼ推定値の結果が誤差なので省略した
以下はコンテスト中・後に思ったことを雑多に書いたものです。
・使っていないものの、ソート済みのアイテムの重さの生成は、遷移3で述べた初期推定値の式を参考にすると多分O(NlogN)ではなくO(N)でできる
・各ケースでの順位によるスコア計算、良いアルゴリズムがかなり母集団によらないか・・・?(基本的には多くの人が到達する解に+αした点に到達できるプログラムがある程度強く、今回だと、第一の波として順番にアイテムを配置した初期解、第二の波として初期解から最大の袋から最小の袋へ移動させる遷移の局所解がありそう。クエリ数が多い場合で最適解を求めてくるみたいな異常集団の波もあるかと思ったがさすがにそんなことはなかった)
・遷移2を実装して「これからクエリ数の大きいケースについて最適解に近づけていくぞ」という気持ちになっていたところ、たまたま起きてしまったREによりクエリ数の大きいケースの失点は大した問題になっていないことが分かってしまった(重さ順を確認するケースは暫定テストで58ケースあり、ここでの失点は0.3Mだったので、当時のスコアから他42ケースで3M近く落としていたことが分かった)ので、最適解方向の話は打ち切ってクエリ数が小さい時の安定化を考えることになった。
・今回の点数は100Mから各ケースで順位を落とした分だけ下がるので、遷移2により90Mくらいまでは上がりやすかったものの97M→98Mへの改善が思ってた以上にかなり遠かった・・・(この試行錯誤の間に他の人も良くなったプログラムを提出して少しずつ各ケースでの争いが激しくなっていたのもあるかもしれない)
・「アイテムの重さ、一番当たりそうな数字を言ってください」といわれると1なのだが、もちろんこんな推定がいいわけがなく・・・。
・マージソートやLargest Differencing Methodなどがコンテスト後に話題になっていた。確認してみるとどちらも今のプログラムに取り入れられる部分があるなあとなり反省。
・いろいろな方の解法ツイートや記事を見る感じ、割と基本的な方針はみんな同じなのかな?遷移をどうするかと推定方法(あるいは推定しない)が何パターンかありそう。
・simanさんが作ってくださった統計を見るに、無事安定志向のプログラムになっていそう。途中でクエリが小さいほうの対策をしていなかったら悲惨なことになってただろうな・・・。統計によってNに対してそれぞれどのような方針が有効なのかが何となく透けて見えるのも面白い。